Problem:
`closeSession()` was called synchronously from the runtime selector action path. Closing an active ACP session can block while closing stdio transport streams. In practice this can park the Swing UI thread in `AcpProtocolCore.close()` / `StdioTransport.close()`, leaving IntelliJ black-screened until the child ACP
process is killed externally.
A freeze report captured the EDT stuck under:
- `AgentModelComboBoxAction.actionPerformed`
- `ExternalAcpAgentService.closeSession`
- `AcpProcessState.close`
- `AcpProtocolCore.close`
- `StdioTransport.close`
- `FileDescriptor.close0`
Changes:
- Close removed ACP process states asynchronously on the service IO scope.
- Remove the session setup mutex immediately after removing the state.
- Stop the child ACP process before closing the protocol.
- Force-kill the child process if it does not exit shortly after `destroy()`.
- Log cleanup failures instead of propagating them back through the UI action path.
Test-Locally
- Reproduced locally with OpenCode -> Codex switching causing IntelliJ to freeze.
- Verified the same close-order patch locally stopped the freeze by letting the ACP process terminate before protocol cleanup.
* Critical edit field bug fix
- Fixed issue when attached files were over 1 line, no more text input were accessible
- Adjusted edit lines to 2 instead of 1 for better view
* Generate commit message with AI fixed
Fixed crashing and non working generate commit message with AI
* Add edit mode default value switch to settings
Added in settings controls to enable/disable edit mode default setting in chat
* Setting to save attached files to chat
Implemented settings param to save attached to chat files. Implemented logs
* refactor: remove code and adjust UI
---------
Co-authored-by: Carl-Robert Linnupuu <carlrobertoh@gmail.com>
Added fields in settings to manually set max overall context and max output context for calculation in agent mode. Default values were too low and didn't count specific model specs. Now it's solved
Fixed diagnostics being broken + added diagnostics as tool for agent. Now it shows relevant files and can filter errors separately.
Fixed Custom OpenAI providers being broken in Agent mode. None worked previously, was streaming bug issues for both
Also passes actual search text to group lookups instead of empty string, adds early termination (200 file cap) to prevent full project tree scans, and deduplicates merged results.
* add middle-click to remove files from context.
Previously when you wanted to remove files which were previously added to the chat context, you had to click the little "x" icon one by one. When you had several files to remove, this got tedious and difficult, especially since the file box varies in width, so the "x" is not in the same space.
This change makes this operation easier by allowing you to middle-click anywhere on the file box to remove it.
* fix: mouse actions when clicked outside of the tag label
---------
Co-authored-by: Carl-Robert Linnupuu <carlrobertoh@gmail.com>
This change makes it so the user can select the key combination to send the message. Users may configure any combination of ctrl, alt, or shift (or the mac equivalents) plus enter. If any are configured, that combination plus enter will send the message, and enter by itself will insert a newline. If none are configured, enter by itself and any of the modifiers plus enter inserts a newline. This means the previous behavior of shift+enter to insert a newline is preserved.
Previously when a message wass deleted, the Conversation object was modified in memory but not correctly updated in the master list of conversations (ConversationsState.conversations). The effect of this was that when you sent a new message, the deleted messages were resurrected.
Previously when text was enclosed in backticks, that text wouldn't wrap, and would instead overflow beyond the viewport. In addition, there is no horizontal scroll bar, so the text is completely inaccessible. And to make it even worse, because of this, the virtual viewport was extended, causing other non-backtick text to also go out of view.
This fixes the issue by overriding the style to enable wrapping.
Previously there was an issue where if a code block contained nested triple-backticks, it would end the code block, causing the message window to become horribly mangled.
This fixes the issue by only considering a triple-backtick to be an end to the code block if the triple-backticks are at the same indention level which started the code block.
* add separate Ollama model selection for code completion
closes issue #733
* add separate selection of code completion provider
closes issue #804
* add test for Ollama code completion with separate model selection
also added missing clearing of code completion cache to other tests. This fixes ProxyAI test - before the fix it was passed always regardless of real ProxyAI completion operation
* fix saving of code completion provider option in IDE settings
* fix code style
* fix: remove expected failing test
---------
Co-authored-by: Carl-Robert Linnupuu <carlrobertoh@gmail.com>
* feat: add Kotlin inferred type analyzer
* feat: implemented a queue with support for maximum crawl depth
* feat: added the depth of analysis setting to end the chat
* feat: added the depth of analysis setting to code completion
* feat: add tag for code analysis
# Conflicts:
# src/main/kotlin/ee/carlrobert/codegpt/ui/textarea/PromptTextField.kt
* feat: changed priority of EditorTagDetails and FileTagDetails
If we added a file when opening a tab, and then added the same file through the "Include files in Prompt..." menu, it will not be in the selected state.
---------
Co-authored-by: alexander.korovin <alexander.korovin@vk.team>
Co-authored-by: Carl-Robert Linnupuu <carlrobertoh@gmail.com>
* feat: use GoogleCompletionRequest.systemInstruction for system prompt
* fix(test): req body assertion
---------
Co-authored-by: Carl-Robert Linnupuu <carlrobertoh@gmail.com>
* Added a keyboard shortcut to remove tags from an active chat
* Replace Main.immediate dispatcher to EdtDispatcher
---------
Co-authored-by: alexander.korovin <alexander.korovin@vk.team>
* Add support for custom baseHost for Anthropic provider
https://github.com/carlrobertoh/ProxyAI/issues/697
* Use intellij-provided socket factory and trust manager for default client
---------
Co-authored-by: borgotta <paul.khattu@gmail.com>
* Change SwingDispatcher to Dispatchers.Main.immediate
* Change PSI analyzer package
* Added a blank for PSI analysis in the chat
* Add support for code structure analysis and improve tag management
- Refactor TagManager to use thread-safe collections
- Add support for new tag types (EditorTagDetails, FileTagDetails)
- Update UI components to handle structure analysis
- Add new icon for structure tags
* Refactoring tags v2
* Add PSI structure to chat settings
* Add VirtualFile to ClassStructure and improve PSI token tracking
* Support passing PSI structure to completion requests
* Add removeListener method to TagManager and fix memory leak
* Update buildOpenAIMessages to support PSI structure for all providers
* Add selected editor tag when initializing user input header
* Add chat settings configuration screen
* Remove unused editor tag and PSI structure settings panels
---------
Co-authored-by: a.iudin <a.iudin@vk.team>
* Initial changes to switch to multiple custom providers
* Change CredentialKey from enum to sealed class
* Changes in the form of settings, support for saving and other logic
* Add copy service settings logic
* Add service settings migration logic
* Fixed the error of working with passwords on the main thread, added api token cleanup for remote settings
* Check style fix
---------
Co-authored-by: a.iudin <a.iudin@vk.team>
* Gradle wrapper 8.11
* Use Ollama API for FIM
* Shorten long line
* Allow optionally overriding ollama FIM template
* fix: configurable actions
* feat: improve UX
---------
Co-authored-by: Carl-Robert Linnupuu <carlrobertoh@gmail.com>
* feat: consolidate all prompts into a single configurable
* feat: implement prompts settings view
* feat: use prompts from PromptsSettings state
* feat: use startInNewWindow settings value
* fix: landing view action placeholder
* feat: update default chat prompts
- Updated the model version for the OpenRouter configuration in the custom OpenAI provider from `meta-llama/llama-3-8b-instruct:free` to `meta-llama/llama-3.1-8b-instruct:free`
* feat: support personas
* fix: replace previous system prompts with personas
* feat: add persona toolbar label
* refactor: rename properties
* refactor: clean up
* fix: personas settings configurable state
* refactor: code cleanup
* feat: list item auto highlightning
* feat: replace personas toolbar label with action link
* refactor: code cleanup
* fix: manual items not being able to delete
* fix: personas settings configurable state
* refactor: clean up code
* fix: folder selection
* feat: support personas
* fix: replace previous system prompts with personas
* feat: add persona toolbar label
* refactor: rename properties
* refactor: clean up
* fix: personas settings configurable state
* refactor: code cleanup
* feat: list item auto highlightning
* feat: replace personas toolbar label with action link
* refactor: code cleanup
* fix: manual items not being able to delete
* fix: personas settings configurable state
* refactor: clean up code
* fix: folder selection
* fix: Updated Ollama settings to sort models and add available models.
1) sort ollama models list when select the model from settings
2) fix: settings of cached ollama models need update
3) sort cached ollama models
* remove code comments
* remove code comments
---------
Co-authored-by: neo <yifei0727@no-reply.users.github.io>
* fix: Updated Ollama settings to sort models and add available models.
1) sort ollama models list when select the model from settings
2) fix: settings of cached ollama models need update
3) sort cached ollama models
* remove code comments
* remove code comments
---------
Co-authored-by: neo <yifei0727@no-reply.users.github.io>
* feat: Show server name in start/stop notifications
* feat: Show opposite action in notification
* feat: Pre-select biggest downloaded parameter size on model change
* chore: Update to latest llama.cpp fixes (2024-05-14)
* feat: Show server name in start/stop notifications
* feat: Show opposite action in notification
* feat: Pre-select biggest downloaded parameter size on model change
* chore: Update to latest llama.cpp fixes (2024-05-14)
* fix: extract services to their own configurables
* feat: switch to selected provider automatically upon apply
* fix: credentials loading at once
* fix: rename llama.cpp title
* Initial implementation of Ollama as a service
* Fix model selector in tool window
* Enable image attachment
* Rewrite OllamaSettingsForm in Kt
* Create OllamaInlineCompletionModel and use it for building completion template
* Add support for blocking code completion on models that we don't know support it
* Allow disabling code completion settings
* Disable code completion settings when an unsupported model is entered
* Track FIM template in settings as a derived state
* Update llm-client
* Initial implementation of model combo box
* Add Ollama icon and display models as list
* Make OllamaSettingsState immutable & convert OllamaSettings to Kotlin
* Add refresh models button
* Distinguish between empty/needs refresh/loading
* Avoid storing any model if the combo box is empty
* Fix icon size
* Back to mutable settings
There were some bugs with immutable settings
* Store available models in settings state
* Expose available models in model dropdown
* Add dark icon
* Cleanups for CompletionRequestProvider
* Fix checkstyle issues
* refactor: migrate to SimplePersistentStateComponent
* fix: add code completion stop tokens
* fix: display only one item in the model popup action group
* fix: add back multi model selection
---------
Co-authored-by: Carl-Robert Linnupuu <carlrobertoh@gmail.com>
This streamlines changes to ServiceType, where any additions or removals will be flagged at compile time to be handled, instead of silently falling back to a default value.
* Add code completion setting states for custom service
* Add settings for code completion in Custom OpenAI service
* Move code completion section to the bottom
* Create test testFetchCodeCompletionCustomService
* Add Custom OpenAI to the "Enable/Disable Completion" actions
* New configuration UI separating /v1/chat/completions from /v1/completions
* Code completion for Custom Service
* Formatting fixes
* Move prefix and suffix to templates in body
* Message updates
* New tabbed UI for Chat and Code Completions
* convert to kotlin, improve ui and other minor changes
* fix test connection for chat completions
* add help tooltips
* allow backward compatibility
* support prefix and suffix placeholders
* fix initial state loading
---------
Co-authored-by: Jack Boswell (boswelja) <boswelja@outlook.com>
Co-authored-by: Carl-Robert Linnupuu <carlrobertoh@gmail.com>
* Stream completion results and cancel early on newline
* Rename 'suggestion, needCancel' to 'message, cancel'
* Replace cancelCurrentCall() with eventSource.cancel() for simplicity
* remove isStreaming variable and onComplete() method
* fix: do not trigger completed callbacks during streaming
---------
Co-authored-by: lichuang <lichuanglai8@163.com>
Co-authored-by: Carl-Robert Linnupuu <carlrobertoh@gmail.com>
* fixes#432 adds support for Placeholders in Prompts
- activate gradle plugin Git4Idea
- adds PlaceholderUtil
- adds DATE_ISO_8601 PlaceholderReplacer
- adds BRANCH_NAME PlaceholderReplacer
* convert to kotlin, improve ui and add int. test
* fix: do not reuse projects from previous test runs
---------
Co-authored-by: Carl-Robert Linnupuu <carlrobertoh@gmail.com>
* chore(deps): Update and centralize dependencies
* Update treesitter to 0.22.2
* Update kotlin to 1.9.23
* Update jackson to 2.17.0
* Update gradle-intellij-plugin to 1.17.3
* Update gradle to 8.7
* Use BOMs where possible
* Centralize dependencies in version catalog
* Allow Dependabot to update other modules (add treesitter and buildSrc/src/main/kotlin, remove core)
* fix: preload credentials only once for all headers
* feat: add OpenAI and Claude vision support
* refactor: replace awaitility with PlatformTestUtil.waitWithEventsDispatching
* feat: display error when image not found
* chore: bump llm-client
* feat: configurable file watcher and minor code cleanup
* fix: ensure image notifications are triggered only for image file types
* docs: update changelog
* fix: user textarea icon button behaviour
* refactor: minor cleanup
* Implement support for You Pro modes: Default, Agent, Custom with various 3rd party models and Research
* Update list of You modes/models depending on user having subscription
* add default value for chatMode
* Add setting to use existing Llama server
* minor UI improvements
* support infill template configuration
---------
Co-authored-by: Carl-Robert Linnupuu <carlrobertoh@gmail.com>
* Add first draft of inline code completion with mock text
* Adds InsertInlineTextAction for inserting autocomplete suggestion with tab
- Changed to disable suggestions when text is selected
- Adds and removes the insert action based on when it shows the inlay hint
* Request inline code completion
* Move inline completion prompt into txt file
* Add inline completion settings to ConfigurationState
* Fix code style
* Use EditorTrackerListener instead of EditorFactoryListener to enable inline completion
* Code completion requests synchronously without SSE
* Use LlamaClient.getInfill() for inline code completion
* support inlay block element rendering, clean up code
* Use only enclosed Method or Class contents for code completion if possible
* Refactor extracting PsiElement contents in code completion
* bump llm-client
* fix completion call from triggering on EDT, force method params to be nonnull by default
* refactor request building, decrease delay value
* Trigger code completion if cursor is not inside a word
* Improve inlay rendering
* Support cancellable infill requests
* add statusbar widget, disable completions by default
* Show error notification if code completion failed
* Truely disable/enable EditorInlayHandler when completion is turned off/on
* Add CodeCompletionEnabledListener Topic to control enabling/disabling code-completion
* Add progress indicator for code-completion with option to cancel
* Add CodeCompletionServiceTest + refactor inlay ElementRenderers
* several improvements
- replace timer implementation with call debouncing
- use OpenAI /v1/completions API for completions
- code refactoring
* trigger progress indicator only for llama completions
* fix tests
---------
Co-authored-by: James Higgins <james.isaac.higgins@gmail.com>
Co-authored-by: Carl-Robert Linnupuu <carlrobertoh@gmail.com>
The CodeGPT Telemetry settings screen was previously a 'stand-alone' configuration window under the 'Tools' section of the IDEA settings. Moving it under the parent plugin makes it more apparent and keeps it better organized.
* Add support for some extended parameters of llama.cpp(top_k, top_p, min_p, and repeat_penalty)
Added 'top_k,' 'top_p,' 'min_p,' and 'repeat_penalty' fields to the llama.cpp request configuration. The default values for these fields match the defaults of llama.cpp. If left untouched, they do not affect the model's response to the request.
* Bump llm-client
---------
Co-authored-by: Carl-Robert Linnupuu <carlrobertoh@gmail.com>
* Initial implementation
* Refactor UI related classes and organize imports
* Display selected files notification, include the files in the prompt
* feat: store referenced file paths in the messate state
* feat: add selected files accordion
* feat: update UI
* feat: improve file selection
* feat: support prompt template configuration
* fix: token calculation for virtualfile checkbox tree
* refactor: clean up
* refactor: move labels/descriptions to bundle
* adds: configuration for the commit-message system prompt
this will remove the default file and move it to the code to be overwritten if the user chooses to modify the prompt.
* fix: checkstyle
---------
Co-authored-by: Carl-Robert Linnupuu <carlrobertoh@gmail.com>
* Initial implementation of integrating llama.cpp to run LLaMA models locally
* Move submodule
* Copy llama submodule to bundle
* Support for downloading models from IDE
* Code cleanup
* Store port field
* Replace service selection radio group with dropdown
* Add quantization support + other fixes
* Add option to override host
* Fix override host handler
* Disable port field when override host enabled
* Design updates
* Fix llama settings configuration, design changes, clean up code
* Improve You.com coupon design
* Add new Phind model and help tooltip
* Fetch you.com subscription
* Add CodeBooga model, fix downloadable model selection
* Chat history support
* Code refactoring, minor bug fixes
* UI updates, several bug fixes, removed code llama python model
* Code cleanup, enable llama port only on macOS
* Change downloaded gguf models path
* Move some of the labels to codegpt bundle
* Minor fixes
* Remove ToRA model, add help texts
* Fix test
* Modify description
* Free GPT4 for a month to try
* Free GPT4 for a month to try
* Better tooltip
* Replace toggle component with checkbox and other minor ui improvements
* Add UTM and userId params to You.com completion request
* Fix#145 - web serach results not being displayed despite the flag
---------
Co-authored-by: siilats <keith@siilats.com>
* Make it clear that you.com is free in case people run out of OpenAI credits
* Clear quota exceeded flag on new api key, minor refactoring
---------
Co-authored-by: Carl-Robert Linnupuu <carlrobertoh@gmail.com>
* on quota exceeded suggest user switch to different LLM provider
* Improve insufficient quota handling, add more telemetry actions
---------
Co-authored-by: Carl-Robert Linnupuu <carlrobertoh@gmail.com>
* Ability to edit generated code inside the chat toolwindow
* Improve icon behaviour
* Fix browseFolderListener automatic disposal by recreating the inputs on each action
* Replace label
* Ability to configure custom service
* Add example preset templates, rename module
* Custom service client impl
* Add YOU API integration
* Remove/ignore generated antlr classes
* Remove text completion models(deprecated)
* Remove unused code, fix settings state sync
* Display model name/icon in the tool window
* Update chat history UI
* Fix model/service sync
* Clear plugin state
* Fix minor bugs, add settings sync tests
* UI changes
* Separate model configuration
* Add support for overriding the completion path
* Update Find Bugs prompt
ProxyAI is the leading open-source extension for connecting your locally running LLM with JetBrains IDEs. Enjoy full AI assistance without sending data externally or needing an internet connection.
- **Ollama Integration:** Automatically detect and utilize Ollama-managed models.
- **GGUF Support:** Easily connect custom models.
- **LLaMA C/C++ Integration:** Run various open-source LLMs without third-party software.
## Core Features
ProxyAI offers a wide range of features to enhance your development experience:
### Chat
Get instant coding advice through a ChatGPT-like interface that accepts image input. Ask questions, share screenshots, seek explanations, or get guidance on your projects without leaving your IDE.
**Auto Apply**
Stream AI-suggested code changes directly into your editor. Preview modifications in diff view and
Quickly access and reference your project files and folders for context-aware coding assistance.
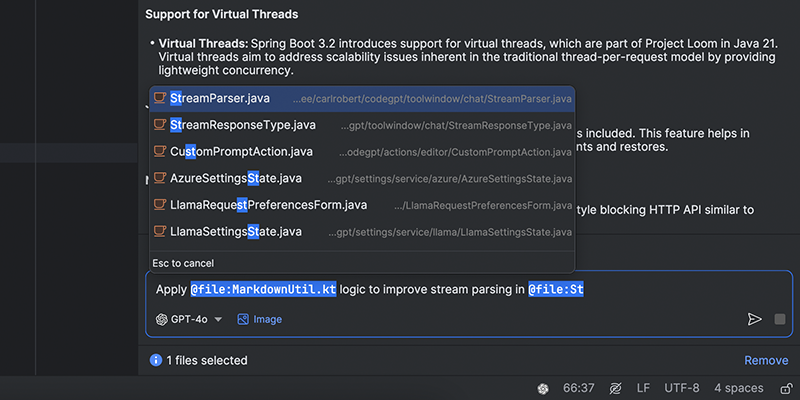
**Reference web documentations**
Easily pull in relevant web documentation into your chat for quick reference—whether it’s API docs, library guides, framework manuals, or something else.
**Search the web**
Connect your favourite LLM to the web. ProxyAI will search for the most relevant information to answer your questions.
**Offline Development Support (llama.cpp and Ollama)**
Integrate local open-source language models into your coding environment and enjoy a full experience without sending your data anywhere or needing an internet connection.

## Privacy
**Your data stays yours.** ProxyAI **does not** collect or store any sensitive information. With users' consent, we collect anonymous usage data to understand how users interact with the extension, including the most-used features and preferred providers.
## License
ProxyAI's code is open source under the Apache License 2.0.
A JetBrains extension that allows you to use ChatGPT inside your favourite IDE
<h1style="margin: 0;"align="center">ProxyAI</h1>
<pstyle="width: 640px">
The leading open-source AI copilot for <atarget="_blank"href="https://plugins.jetbrains.com/plugin/21056-proxy-ai">JetBrains</a>. Connect to any model in any environment, and customize your coding experience in any way you like.
This is an extension for JetBrains IDEs that integrates ChatGPT into your coding environment.
By leveraging the power of GPT-3, this makes it an invaluable tool for developers looking to streamline their workflow and gain a deeper understanding of the code they're working on.
ProxyAI is an AI-powered code assistant designed to help you with various programming activities. It is a great alternative to GitHub Copilot, AI Assistant, Codiumate, or any other extension on the JetBrains marketplace.
## Getting Started
We equip you with the latest models, advanced tools, and on-premise solutions that are designed to significantly enhance your developer experience.
To get started, follow these simple steps:
Access top-tier language models from OpenAI, Anthropic, Azure, Mistral, and others, or opt for a self-hosted model for a full offline experience.
### Prerequisites
## Core Features
In order to use the extension, you need to have a JetBrains IDE installed and the API key configured.
You can find the API key in your [User settings][api-key-url].
ProxyAI offers a wide range of features to enhance your development experience:
### Installation
### Chat
The plugin is available from [JetBrains Marketplace][plugin-repo].
You can install it directly from your IDE via the `File | Settings/Preferences | Plugins` screen.
On the `Marketplace` tab simply search for `codegpt` and select the `CodeGPT` suggestion:
- **Auto Apply:** Stream AI-suggested code changes directly into your editor. Preview modifications in diff view and approve or reject them with a single click.
![marketplace][marketplace-img]
- **Use images:** Chat with your images. Upload manually or let ProxyAI auto-detect your screenshots.
### API Key Configuration
- **Reference your files and folders:** Quickly access and reference your project files and folders for context-aware coding assistance.
After the plugin has been successfully installed, the API key needs to be configured.
- **Reference web docs:** Quickly reference web docs in your chat session, such as API guides, library manuals, and more.
You can configure the key by going to the plugin's settings via the `File | Settings/Preferences | Tools | CodeGPT`.
On the settings panel simply click on the `API key` field, paste the key obtained from the OpenAI website and click `Apply/OK`:
- **Reference git history:** Quickly reference commit logs and changes in your chat session
![plugin-settings][plugin-settings]
- **Search the web:** Connect your favourite LLM to the web. ProxyAI will search for the most relevant information to answer your questions.
## Features
- **Customize your assistant:** Choose between multiple different personas for your specific needs, whether you're looking to learn, write or proofread.
The plugin provides several key features, such as:
### Code
### Ask ChatGPT
Ask anything you'd like.
- **Next edits:** Get multi-line edits based on your recent activity as you type.
Stop the response generation or re-generate a new response from the existing query.
**Tailing logs**
```shell
tail -f build/idea-sandbox/IU-2026.1/log/idea.log
```
<palign="center">
<imgsrc="docs/assets/gif/stop-reload.gif"/>
</p>
## Privacy
## Roadmap
**Your data stays yours.** ProxyAI **does not** collect or store any kind of sensitive information.
- [x] Add proxy support
- [ ] Add conversation history
- [x] Ability to start/restore sessions
- [ ] Ability to export conversations in Markdown/JSON format
- [ ] Add codex and user's fine-tuned models
- [ ] Add support for overriding prompts and request params
- [ ] Add support for custom fonts, colors and sizes
- [ ] Add support for model fine-tuning
However, with users' consent, we do collect anonymous usage data, which we use to understand how users interact with the extension, including the most-used features and preferred providers.
See the [open issues][open-issues] for a full list of proposed features (and known issues).
## Feedback
## Contributing
Your input helps us grow. Reach out through:
Contributions are what make the open source community such an amazing place to learn, inspire, and create. Any contributions you make are **greatly appreciated**.
If you have a suggestion that would make this better, please fork the repo and create a pull request. You can also simply open an issue with the tag "enhancement".
1. Fork the Project
2. Create your Feature Branch (`git checkout -b feature/AmazingFeature`)
3. Commit your Changes (`git commit -m 'Add some AmazingFeature'`)
4. Push to the Branch (`git push origin feature/AmazingFeature`)
This example logs every tool call to a file. It's useful when you're debugging an agent, trying to understand why it made a decision, or just want a paper trail.
Add a hooks config to `.proxyai/settings.json`:
```json
{
"ignore": [],
"permissions": { "allow": [] },
"hooks": {
"afterToolUse": [
{
"command": ".proxyai/hooks/tool-audit.sh",
"timeout": 10
}
]
}
}
```
Create the hook script:
```bash
#!/usr/bin/env bash
set -euo pipefail
# .proxyai/hooks/tool-audit.sh
# Read the JSON payload ProxyAI sends on stdin.
payload=$(cat)
# Append one JSON object per line.
# (If you prefer pretty logs, pipe through jq in your own version.)
Once the settings file is saved, ProxyAI picks up the hook configuration automatically.
## Hook types
ProxyAI hooks are command-based.
You provide a `command` to run (typically a shell script). ProxyAI feeds the hook a JSON payload on stdin and captures JSON output on stdout (if you produce any).
```json
{
"hooks": {
"beforeShellExecution": [
{
"command": ".proxyai/hooks/approve-network.sh",
"timeout": 30,
"matcher": "curl|wget|nc"
}
]
}
}
```
## Configuration
Configure hooks in your project's `.proxyai/settings.json`. Each hook event (for example `afterFileEdit`) maps to an array of hook entries.
### Working directory
Hooks run from the project root.
- Relative paths in `command` resolve from the project root
- Child processes inherit the project root as their working directory
- `PROXYAI_PROJECT_DIR` contains the absolute project path
### Hook settings format
```json
{
"ignore": [],
"permissions": { "allow": [] },
"hooks": {
"preToolUse": [
{
"command": ".proxyai/hooks/validate-shell.sh",
"matcher": "Shell"
}
],
"subagentStart": [
{
"command": ".proxyai/hooks/validate-explore.sh",
"matcher": "explore|shell"
}
],
"beforeShellExecution": [
{
"command": ".proxyai/hooks/approve-network.sh",
"matcher": "curl|wget|nc "
}
]
}
}
```
### Hook fields
| Field | Type | Default | Description |
| --- | --- | --- | --- |
| `command` | string | required | Executable path to a hook script (for example `.proxyai/hooks/tool-audit.sh`). |
| `timeout` | number | `30` | Optional timeout value in seconds (defaults to 30 if not set). |
| `matcher` | string | `null` | Optional matcher string (used to filter when hook runs). |
| `enabled` | boolean | `true` | Whether the hook is active. |
### Matcher behavior
If `matcher` is provided, it is evaluated against a target string that depends on the event:
- `preToolUse`, `afterToolUse`: tool name (for example `Bash`).
- `beforeShellExecution`, `afterShellExecution`: full command string.
- `beforeReadFile`, `afterFileEdit`: file path.
- `subagentStart`, `subagentStop`: subagent type.
- `stop`: status or reason.
Matcher uses regex if valid; otherwise it falls back to substring matching.
### Timeout behavior
Hooks that exceed their timeout are forcibly terminated and treated as failures. This prevents hung hook scripts from blocking the agent indefinitely. The default timeout is 30 seconds.
### Hook execution order
When multiple hooks are configured for the same event:
1. All matching hooks (based on `enabled` flag and `matcher`) execute in order
2. Each hook runs independently; failure of one doesn't stop others
3. Any hook returning a deny decision prevents the action
4. Hooks are executed sequentially, not in parallel
## Hook generation
If you prefer not to write hooks by hand, you can generate a hook from natural language in the UI.
### Steps
1. Open settings and go to Hooks.
2. Click **Generate**.
3. Describe what you want (for example: "Log every tool execution to a file for auditing").
4. Review the preview:
- Event (you can change which event triggers the hook)
- Command, matcher, and timeout
- Generated script content
5. Click **Add Hook** to save:
- Scripts are written to `.proxyai/hooks/` in your project.
- The hook entry is added to `.proxyai/settings.json`.
### Notes
- Generated scripts are marked executable on macOS/Linux. On Windows, you may need to adjust how the script is invoked.
- Generation uses the configured agent model and can take a few seconds.
## How hooks work
When a hook runs, ProxyAI launches your command and sends it a JSON payload on stdin.
Your hook can:
- Do nothing and exit (for logging-only hooks)
- Print JSON on stdout to allow/deny the action
- Print JSON on stdout to rewrite the tool input or output
### Runtime details
| Item | Description |
| --- | --- |
| Input | JSON payload on stdin. |
| Common field | `hook_event_name` is included in every payload. |
| Working directory | Project root directory (`{projectRoot}/.proxyai/`). |
| Visibility | Hook runs appear in the tool output panel (event, hook name, status, details). |
Use `beforeShellExecution` to deny high-risk command patterns.
```bash
#!/usr/bin/env sh
set -eu
# Consume JSON payload from stdin.
cat >/dev/null
# Exit code 2 means "deny".
printf '{"reason":"Blocked by project policy: this command is not allowed."}\n'
exit 2
```
Configuration:
```json
{
"hooks": {
"beforeShellExecution": [
{
"command": ".proxyai/hooks/block-command.sh",
"matcher": "rm -rf|terraform apply|docker system prune"
}
]
}
}
```
### Prefer settings.json for path restrictions
If your goal is to protect files or folders, prefer `.proxyai/settings.json` `ignore` patterns over hooks. Ignore patterns are simpler and apply consistently across tools.
- Use `ignore` for path-level protection (for example `.env`, `.git/`, `node_modules/`)
- Use hooks when you need command-level policy checks
- See [Ignore Rules](/agent/security/ignore-rules) and [Permissions](/agent/security/permissions) for baseline guardrails
## Event reference
### preToolUse
Called before any tool execution. This is a generic hook that fires for all tool types.
description: How the ProxyAI agent works, what it can do, and how it runs tasks.
---
# Agent
The Agent is ProxyAI's autonomous mode for multi-step work. It plans and executes tasks, calls tools on your behalf, and can delegate specific work to subagents when it needs focused help.
## What it can do
- Plan and execute multi-step work with approvals for risky actions
- Support multi-turn conversations by asking clarifying questions when needed
- Read, search, edit, and run commands across your project
- Inspect prior runs, roll back changes, and continue from checkpoints with [Timeline](/agent/timeline)
- Delegate focused work to [Subagents](/agent/subagents)
- Load reusable instruction packs with [Skills](/agent/skills)
- Extend and control runs with [Hooks](/agent/hooks) (for example: block risky operations, log tool usage, build usage dashboards)
- Follow project-specific instructions from a `PROXYAI.md` file at the repo root
- Run with many different models and providers (see [Providers](/providers/overview))
- Automatically compress long-running context to stay within model limits
## Where to go next
- Learn how specialized agents work in [Subagents](/agent/subagents)
- Work with checkpoints and rollback using [Timeline](/agent/timeline)
- Define reusable instruction packs in [Skills](/agent/skills)
- Configure guardrails in [Security](/agent/security)
- Customize automation with [Hooks](/agent/hooks)
- See the available tools in [Tools](/agent/tools)
description: Delegate focused tasks to specialized agents with controlled tool access.
---
# Subagents
Subagents are specialized agents launched by the main Agent through the `Task` tool. They let the main agent delegate focused work (like exploration or implementation) while keeping tool access and behavior scoped.
## Custom subagents
Custom subagents are user-defined agent profiles. You can create them either in the UI or by editing your config file.
Each custom subagent has:
- A **title** (this is the value you pass in `subagent_type`)
- An **objective/behavior** description
- An optional **runtime override**
- A **tool allowlist** that controls what it can do
### Create in the UI
1. Open settings and go to Subagents.
2. Click **Add** (or **Generate** if you want ProxyAI to draft it from a prompt).
3. Set the title, objective, runtime, and allowed tools.
4. Save.
### Create via settings.json
You can also add subagents directly in your project's `.proxyai/settings.json`.
**Subagent definition fields**
| Field | Type | Required | Description |
| --- | --- | --- | --- |
| `id` | number | Yes | Unique numeric ID for this subagent. |
| `title` | string | Yes | Display name and the value you pass as `subagent_type`. |
| `objective` | string | Yes | Instructions that shape how the subagent behaves. |
| `tools` | string[] | Yes | Allowed tools, stored as lowercase tool IDs (for example `read`, `intellijsearch`, `edit`). |
| `provider` | string | No | Native provider override. Must be paired with `model`. |
| `model` | string | No | Native model override. Must be paired with `provider`. |
| `external_agent_id` | string | No | External ACP runtime preset ID (for example `codex`). |
If you omit `provider`, `model`, and `external_agent_id`, the subagent inherits the parent Agent runtime.
Example:
```json
{
"subagents": [
{
"id": 200,
"title": "Dependency Researcher",
"objective": "Help choose the best dependency for the user's topic (e.g., auth, logging, HTTP, testing). Compare 2-4 realistic options, call out licensing, maintenance signals, and ecosystem fit. Prefer reading existing repo usage first, then use Context7 for API details, and WebSearch only for release notes/security/official docs. Provide a short recommendation with sources.",
"provider": "OPENAI",
"model": "gpt-5-mini",
"tools": [
"read",
"intellijsearch",
"resolvelibraryid",
"getlibrarydocs",
"websearch",
"todowrite",
"exit"
]
}
]
}
```
## Generate subagents
If you don't want to hand-write subagent definitions, you can generate one from natural language in the UI.
### Steps
1. Open settings and go to Subagents.
2. Click **Generate**.
3. Describe what you want (for example: "Review Kotlin code for style and complexity").
4. Review the generated title and objective.
5. Adjust the tool allowlist if needed, then save.
### Notes
- Generation creates the title and objective text. Tool access is suggested based on your prompt, but it's still your call.
- If your prompt includes words like "edit", "implement", or "modify", ProxyAI will usually suggest write-capable tools.
## Task input reference
When the agent spawns a subagent, it calls the `Task` tool with the inputs below.
| Field | Type | Required | Description |
| --- | --- | --- | --- |
| `description` | string | Yes | Short label for the run. |
| `prompt` | string | Yes | Full instruction for the subagent. |
| `subagent_type` | string | Yes | Which subagent to run (built-in type or a custom title). |
| `model` | string | No | Optional native-model override for that subagent run. ProxyAI rejects this when the resolved runtime is external. |
| `project_path` | string | No | Optional working directory override. |
## How subagents are surfaced
Subagent tool calls are bridged back to the parent agent run so the UI can display them and approval prompts still work as expected.
The task row also shows the resolved runtime as soon as the subagent starts, for example:
- `OpenAI · GPT-5`
- `Anthropic · Claude 4.5 Sonnet`
- `Codex`
## See also
- [Tools](/agent/tools) for the tool registry and schemas.
- [Skills](/agent/skills) for on-demand reusable instructions.
- [Hooks](/agent/hooks) for `subagentStart` and `subagentStop`.
description: Inspect past agent runs, roll back changes, and branch into a new session from any checkpoint.
---
# Agent Timeline
Agent Timeline lets you move through a session's history as a sequence of runs and checkpoints. You can inspect what happened, copy outputs, roll back file changes, and continue from an earlier point.
## Open the timeline
1. Open an **Agent** tab that already has at least one completed run.
2. In the input toolbar, click the **Timeline** (history) icon.
3. Select a run/checkpoint from the timeline tree.
If a run is still active, stop it first. Timeline context editing is blocked while the session is running.
## How the timeline is organized
- The dialog groups history by **Run 1, Run 2, ...**.
- Each run contains checkpoints for user messages, assistant responses, reasoning messages, and tool calls.
- Thinking blocks (`<think>...</think>`) are stripped from visible assistant text.
## Right-click actions
Right-click any checkpoint row to open actions:
- **Rollback**: Rewinds file changes and syncs the current session view back to that point.
- **Continue From New Session**: Creates a new Agent tab starting from the selected checkpoint.
- **Copy Output**: Copies output for assistant/reasoning/tool-call entries.
You can also double-click a checkpoint (or press `Enter`) to continue from that point in a new session.
## Edit session context
Click **Edit** to enter context selection mode:
- Check or uncheck full runs or individual checkpoints to decide what stays in context.
- Watch the context stats label (`messages` and estimated `tokens`) update as you select.
- Click **Apply** to rewrite the current tab's session context.
- Click **New Session** to create a fresh tab from the selected context.
When you select assistant/tool checkpoints, ProxyAI keeps required linked messages (for example the matching user prompt or tool result) so the history stays coherent.
## Rollback behavior
Rollback is run-aware:
- For the current run, ProxyAI uses tracked run snapshots and shows a confirmation list of changed files.
- For older checkpoints, ProxyAI reconstructs reversible `Edit`/`Write` operations from checkpoint history and applies them in reverse order.
If a file has diverged too far from expected content, rollback can be partial and ProxyAI will show which operations failed.
description: "Tool reference: inputs, outputs, and approval behavior."
---
# Tools
This is the reference for ProxyAI's built-in tools: what each tool does, what inputs it accepts, and what it returns. Tools are the contract between the model and your machine. If something feels "magical", it usually maps to one of these tools.
## Quick map
- Need to inspect a file? Use **Read**.
- Need to find a file/symbol name-first? Use **IntelliJSearch**.
- Need to change files? Use **Edit** (precise replace) or **Write** (create/overwrite).
- Need to run commands? Use **Bash**, and monitor with **BashOutput**.
- Need content from a specific URL? Use **WebFetch**.
- Need to delegate? Use **Task**.
- Need reusable workflow instructions? Use **LoadSkill**.
## Approvals
The UI asks for approval for:
- **Edit** and **Write**
- **Bash**
For path-level restrictions, see [Ignore Rules](/agent/security/ignore-rules). For tool allow rules (`Bash`, `Read`), see [Permissions](/agent/security/permissions).
## Tool reference
### Read
Reads a file from disk and returns it in numbered `cat -n` format.
**Input**
| Field | Type | Required | Notes |
| --- | --- | --- | --- |
| `file_path` | string | Yes | Must be an absolute path. |
| `offset` | number | No | 1-indexed line offset. |
| `limit` | number | No | Number of lines to read. |
**Output**
| Field | Type | Notes |
| --- | --- | --- |
| `filePath` | string | Echoes the path requested. |
description: Using images as context within ProxyAI chat.
---
import Image from 'next/image'
# Image Context
Chat with your images directly within ProxyAI. Upload screenshots, diagrams, or error messages and let the AI analyze them for you.
## How it Works
When you share an image with ProxyAI, the AI analyzes what it sees. This works especially well with:
- Screenshots of error messages
- UI mockups or interfaces
- Diagrams and flowcharts
- Code snippets captured as images
The AI can describe what it sees, explain diagrams, help with UI elements, extract text, or troubleshoot errors shown in your images.
## Adding Images
You can add images to your chat in two ways:
- **Manual Upload:** Click the upload button in the chat interface or simply drag and drop an image.
- **Auto-detect Screenshots:** Enable this feature in settings to have ProxyAI monitor for new screenshots. When you take a screenshot, ProxyAI will offer to add it to your current conversation.
You can turn screenshot detection on or off from: **Settings/Preferences > Tools > ProxyAI > Configuration > Check for new screenshots automatically**.
description: Overview of ProxyAI chat capabilities within the IDE.
---
# Context Overview
Context is what helps ProxyAI understand your specific situation. Without context, the AI can only provide generic responses. With context, it can deliver precise, relevant assistance.
## @ Symbols
Use @ symbols to quickly add context to your conversations:
* **Code:** Include code snippets from your project
* **Files & Folders:** Reference specific project files and directories
* **Git:** Use commit history and recent changes as context
* **Web:** Allow the AI to perform web searches for up-to-date information
* **Documentation:** Fetch content from external documentation URLs
* **Images:** Analyze images like screenshots and diagrams
## Personas
Switch between different AI personalities based on your current task. Choose specialized personas for code writing, explaining concepts, proofreading, or create custom ones.
## Images
Share screenshots, diagrams, or error messages directly in chat. ProxyAI can analyze visual content to troubleshoot problems or explain what it sees.
description: Customize AI behavior with different personas in ProxyAI chat.
---
import Image from 'next/image'
# Personas
Use personas to change how ProxyAI responds to you. You can adjust the AI's tone, style, and focus. This helps you get better results for specific tasks, like learning new concepts, writing code, or proofreading text.
## Create a Persona
You create and manage your personas in the plugin settings.
1. Go to **Settings/Preferences > Tools > ProxyAI > Prompts**.
2. Find the section for managing personas. Add your new persona instructions there.
Choose your default persona in the settings (**Settings/Preferences > Tools > ProxyAI > Prompts**). ProxyAI uses this persona for all your chat conversations automatically, unless you override it for a specific session.
### Use a Persona for One Session
Need a different persona just for the current chat? Use the `@Personas` symbol.
1. Type `@` in the chat input.
2. Select `Personas` from the list that appears.
3. Choose the specific persona you want to use.
This selection applies only to the current chat session. It temporarily overrides your default persona.
Learn more about using context symbols like `@Personas` in the [@ Symbols Overview](/context/symbols/overview).
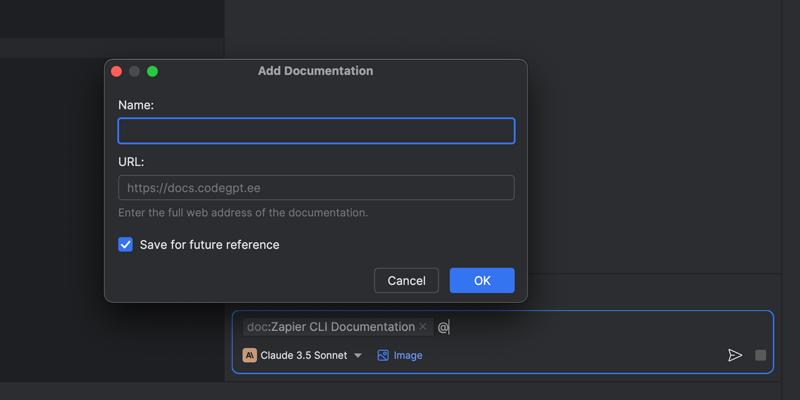
description: Integrating external documentation directly into the chat.
---
# Documentation Context
Easily pull relevant web documentation into your chat for quick reference and AI analysis. Whether it’s API documentation, library guides, framework manuals, or technical articles, ProxyAI can fetch and utilize this content.
description: Referencing project files and folders within ProxyAI chat.
---
import Image from 'next/image'
# Files & Folders Context
Quickly access and reference your project files and folders within the chat, enabling ProxyAI to provide context-aware coding assistance based on your project structure and content.
description: Using Git history as context in ProxyAI chat.
---
# Git Context
Integrate your project's Git history directly into your ProxyAI chat sessions. This allows the AI to understand changes over time, specific commits, and recent development activity.
## Referencing Commits
You can include one or more specific Git commits in your chat message. This is useful for:
* **Code Review:** Ask the AI to review the changes introduced in a specific commit.
* **Understanding Changes:** Request an explanation of the modifications made in a commit.
* **Debugging:** Provide context about when a potential issue might have been introduced.
* **Generating Summaries:** Ask the AI to summarize the purpose of a commit based on its changes.
## Referencing Recent Changes
Besides specific commits, you can also provide the AI with the context of all recent, uncommitted changes in your working directory or staged changes. This is useful for:
* **Pre-commit Reviews:** Get feedback on your current changes before committing them.
* **Generating Commit Messages:** Ask the AI to suggest a commit message based on the staged changes (See also: [AI Commit Message feature](/editor/commit-message)).
* **Explaining Current Work:** Summarize the ongoing modifications for documentation or handover.
Overview of all @ symbols available in ProxyAI for context and commands
When using the chat input box, you can use @ symbols by typing `@`. A popup menu will appear with a list of suggestions, and it will automatically filter to only show the most relevant suggestions based on your input.
You can navigate through the list of suggestions using the up/down arrow keys. You can hit Tab to select a suggestion. If the suggestion is a category, such as Files, the suggestions will be filtered to only show the most relevant items within that category.
Here's the list of all @ symbols available:
- **@Files** - Reference specific files in your project
- **@Folders** - Reference entire folders for broader context
- **@Docs** - Access documentation and guides
- **@Git** - Access git history and changes
- **@Personas** - Reference personas for context and commands
- **@Web** - Reference external web resources and documentation
description: Enable ProxyAI to access and utilize live web search results.
---
# Web Context
Connect ProxyAI to the internet to enhance its knowledge with up-to-date information. When enabled, ProxyAI can perform web searches to find the most relevant context for answering your questions.
When you ask a question that might benefit from current information (e.g., latest library versions, recent news, troubleshooting errors not in its training data), ProxyAI can:
1. Identify the need for external information.
2. Perform a web search based on your query.
3. Analyze and synthesize the search results.
4. Incorporate the relevant findings into its answer.
This allows the AI to provide answers based on the latest documentation, articles, and discussions available online.
description: Manage ProxyAI access for your team with centralized administration and predictable per-seat pricing.
---
# ProxyAI Cloud for Enterprise
ProxyAI Cloud for Enterprise offers the same core AI capabilities as the individual Pro plan but is designed specifically for teams and organizations requiring centralized administration and predictable budgeting.
## Benefits over Pro
* **Centralized Seat Management:** Team leaders or administrators can purchase and assign licenses to developers within their organization through a single dashboard
* **Predictable Pricing:** Simplify budget management with a clear, fixed cost per developer per month. This avoids the complexity and potential variability of managing individual subscriptions or direct API usage costs across a team
* **Consolidated Billing:** Simplify accounting with one subscription and invoice covering all team members
This structure is ideal for organizations needing to provide ProxyAI access to multiple developers while maintaining administrative control, streamlined billing, and predictable expenses for AI tooling.
## Pricing
ProxyAI Cloud for Enterprise is priced per user:
* **Standard Rate:** $20 per developer, per month.
description: A private version of ProxyAI for specific enterprise needs.
---
# ProxyAI Custom Extension
For organizations with specific security, compliance, or customization requirements, we offer a private, custom version of the ProxyAI extension. This version allows for deep integration with your internal infrastructure and workflows, particularly for teams working with sensitive data or using self-hosted AI models.
## Core Features & Benefits
* **In-House Model Integration:** Configure the extension to connect exclusively to your own self-hosted or private cloud AI models (OpenAI API compatible or other custom integrations), without the additional 3rd party providers included as in the public version.
* **Remote Settings Synchronization:** Centrally manage and enforce plugin settings across your entire organization. Learn more about [remote settings sync](/enterprise/remote-settings)
* **Automatic Updates:** The custom extension stays up-to-date with features and improvements from the public ProxyAI version. You can distribute updates through your own [custom plugin repository](https://plugins.jetbrains.com/docs/intellij/custom-plugin-repository.html), giving you complete control over version management while ensuring your team benefits from the latest advancements.
* **Self-Hosted Next Edits:** Option to self-host the model powering the [Next Edits](/editor/tab#next-edits) and configure it against your custom extension, keeping the data entirely within your infrastructure.
* **Other Customization:** Possibility for further customization, such as custom branding or specific feature adjustments to meet unique organizational needs.
## Use Cases
The Custom Extension is designed for enterprises that:
* Operate in regulated industries with strict data privacy and security mandates.
* Work with highly sensitive or proprietary codebases.
* Have invested in self-hosting large language models.
* Require centralized control and standardization of developer tools across large teams.
* Need specific customizations not available in the public version.
## Pricing
Pricing for the private custom extension is determined by your specific needs and scale of your organization.
To discuss your requirements and receive a quote, please contact us at [contact@codegpt.ee](mailto:contact@codegpt.ee).
description: Choose the ProxyAI enterprise solution that best fits your organization's needs for AI integration, security, and management.
---
import Image from 'next/image'
# Enterprise Overview
ProxyAI provides two enterprise solutions designed to integrate AI capabilities into development workflows while addressing specific organizational requirements for security, control, and infrastructure.
1. **ProxyAI Cloud:** A managed service providing access to a diverse set of AI models and features with predictable pricing.
2. **ProxyAI Custom Extension:** A private, configurable version of the ProxyAI plugin for organizations requiring integration with self-hosted AI models and centralized configuration management.
## ProxyAI Cloud
ProxyAI Cloud gives your team simple, managed access to a variety of AI models and features.
**Key Highlights:**
* Access premium proprietary and open-source coding-optimized models
* Predictable seat-based pricing
* Access features like Next Edits and Auto Apply that aren't available through other providers
## ProxyAI Custom Extension
For organizations with strict security, compliance, or specific integration needs, the Custom Extension offers a private, configurable version of ProxyAI.
* Connect exclusively with your **in-house or private cloud AI models** (OpenAI API compatible)
* Control plugin settings across your organization through **[Remote Settings](/enterprise/remote-settings)**
* Optionally **self-host the Next Edits feature** for complete data control
* Receive automatic updates while keeping your custom configuration
* Potential for further customization (branding, features)
Designed for organizations operating in regulated environments, handling sensitive data, using self-hosted models, or requiring extensive customization and control.
description: Centrally manage and synchronize ProxyAI configurations across your organization.
---
import { Callout, Tabs, Tab } from 'nextra/components'
# Remote Settings
Remote Settings provide administrators with the ability to centrally define and distribute ProxyAI configurations to all users within their organization.
### Benefits
* **Consistency:** Ensure all developers use the same AI models, prompts, and configurations.
* **Compliance & Security:** Enforce the use of approved, secure AI endpoints and disable non-compliant features.
* **Simplified Management:** Update configurations centrally without manual changes on each developer's machine.
* **Easier Onboarding:** New team members automatically receive the standard configuration.
This feature is available as part of the **[Custom Extension](/enterprise/custom-extension)**.
## Prerequisites
Before configuring Remote Settings:
1. Identify the AI providers, models, and custom prompts your organization needs.
2. Prepare a secure internal web server or location to host the configuration JSON file.
3. Ensure the hosting URL is accessible from your developers' workstations where ProxyAI is installed.
4. Plan how to distribute the URL to the ProxyAI instances (e.g., via the Custom Extension or direct communication).
## How it Works
Administrators define a standard configuration profile within a JSON file. This configuration file is hosted at a secure internal URL accessible to developers within the organization.
The ProxyAI plugin is configured (either manually by the user or automatically via the Custom Extension) with this URL. ProxyAI then fetches the file and applies the settings defined within it to the user's instance. This synchronization ensures that the user's ProxyAI setup aligns with the centrally managed configuration.
<Callout type="warning">
**Security:** Ensure the URL hosting your configuration JSON is secure and only accessible within your organization's network or via appropriate authentication mechanisms. Avoid exposing sensitive information like API keys directly in this file; use placeholders like `$CUSTOM_SERVICE_API_KEY`.
</Callout>
## Configuration Overview
Remote settings are defined in a single JSON file. The root object can contain `prompts` and `providers` keys. You only need to include the sections you wish to manage centrally.
<Callout type="info" title="Placeholders">
Configuration values can use placeholders that ProxyAI replaces at runtime:
* `$CUSTOM_SERVICE_API_KEY`: User's API key entered in ProxyAI settings (used in `providers` headers).
* `$OPENAI_MESSAGES`: Formatted chat history array (used in `chatCompletionSettings.body`).
* `$PREFIX`: Code before the cursor (used in `codeCompletionSettings.body`).
* `$SUFFIX`: Code after the cursor (used in `codeCompletionSettings.body` for infill).
* `{SELECTION}`: Selected code in the editor (used in `chatActions` prompts).
* `{BRANCH_NAME}`, `{DATE_ISO_8601}`: Git context (used in `coreActions` prompts).
* **`customOpenAI`**: (Array) A list of provider configurations. Each object defines a selectable service endpoint compatible with the OpenAI API format.
#### Provider Object Fields:
* `name`: (String, Required) Display name for the provider in ProxyAI settings (e.g., "Internal Llama 3").
* `template`: (String, Required) API format template.
* `chatCompletionSettings`: (Object, Optional) Settings for chat completions. See details below.
* `codeCompletionSettings`: (Object, Optional) Settings for code completions. See details below.
---
#### `chatCompletionSettings` Fields
Configure the chat API endpoint:
| Field | Type | Required | Description | Example/Placeholder |
| `url` | String | Yes | The full URL of the chat completion API endpoint. | `"https://.../chat/completions"` |
| `headers` | Object | Yes | Key-value pairs for HTTP headers. Use `$CUSTOM_SERVICE_API_KEY` for the user's API key. | `{ "Authorization": "Bearer $CUSTOM_SERVICE_API_KEY", ... }` |
| `body` | Object | Yes | The JSON body structure for the API request. See notes below. | `{ "model": "...", "messages": "$OPENAI_MESSAGES", ... }` |
| `model` | String | Yes (in `body`) | The specific model identifier to use. | `"llama-4-maverick-17b"` |
| `messages`| String | Yes (in `body`) | Placeholder `$OPENAI_MESSAGES`; replaced by the plugin with formatted conversation history. | `"$OPENAI_MESSAGES"` |
| `stream` | Boolean | Yes (in `body`) | Typically `true` to enable streaming responses. | `true` |
| *...other body params* | *Type* | *Optional* | Other parameters supported by your endpoint (e.g., `temperature`, `max_tokens`). | `0.0`, `8192` |
<Callout type="info" title="Note on `chatCompletionSettings.body`">
This object defines the API request payload. It **must** include `model`, `messages` (using the `$OPENAI_MESSAGES` placeholder), and `stream`. Add other parameters like `temperature`, `max_tokens`, `top_p` as needed by your specific endpoint. The `$CUSTOM_SERVICE_API_KEY` placeholder in `headers` is replaced by the API key entered by the user in the plugin settings.
</Callout>
---
#### `codeCompletionSettings` Fields
Configure the code completion API endpoint (optional):
| Field | Type | Required | Description | Example/Placeholder |
| `codeCompletionsEnabled` | Boolean | No | Set to `true` to enable code completions for this provider. Defaults to `false`. | `true` |
| `infillTemplate` | String | No | Specifies how infill requests (prefix/suffix) should be formatted. "OpenAI" is common. Defaults `null`. | `"OpenAI"` |
| `url` | String | If Enabled | The full URL of the code completion API endpoint. | `"https://.../completions"` |
| `headers` | Object | If Enabled | Key-value pairs for HTTP headers. Use `$CUSTOM_SERVICE_API_KEY`. | `{ "Authorization": "...", ... }` |
| `body` | Object | If Enabled | The JSON body structure for the API request. See notes below. | `{ "model": "...", "prompt": "$PREFIX", ... }` |
| `model` | String | Yes (in `body`) | The model identifier for code completion. | `"gpt-3.5-turbo-instruct"` |
| `prompt` | String | Yes (in `body`) | Placeholder `$PREFIX`; replaced by the plugin with code before the cursor. | `"$PREFIX"` |
| `suffix` | String | Yes (in `body`, if infill) | Placeholder `$SUFFIX`; replaced by the plugin with code after the cursor (for infill). | `"$SUFFIX"` |
| `stream` | Boolean | Yes (in `body`) | Typically `true` to enable streaming responses. | `true` |
| *...other body params* | *Type* | *Optional* | Other parameters supported by your endpoint (e.g., `temperature`, `max_tokens`). | `0.2`, `24` |
<Callout type="info" title="Note on `codeCompletionSettings.body`">
The `body` object defines the API request payload. It **must** include `model`, `prompt` (using `$PREFIX`), and `stream`. If using infill (`infillTemplate` is set), it **must** also include `suffix` (using `$SUFFIX`). Add other parameters like `temperature`, `max_tokens` as needed by your endpoint.
</Callout>
<Callout type="info" title="Placeholders for Code Completion">
* `$PREFIX`: Code before the cursor.
* `$SUFFIX`: Code after the cursor (used when `infillTemplate` is active).
* `$CUSTOM_SERVICE_API_KEY`: User's API key (used in `headers`).
</Callout>
</Tab>
</Tabs>
## Applying Remote Settings in ProxyAI
Once your administrator has set up the remote configuration file and provided you with the URL, you can sync these settings within your ProxyAI plugin.
### Manual Sync via Settings
You can manually fetch and apply the latest remote settings at any time:
alt="Notification for applying remote settings updates"
width="1200"
height="800"
className="nx-rounded-lg nx-my-4"
autoPlay
muted
loop
/>
Remember, you can always use the **Manual Sync** option described above if you need to fetch updates without restarting the IDE.
## Example Full Configuration JSON
Below is an example demonstrating how to structure the JSON file with both `prompts` and `providers` defined. Host this file at a secure internal URL accessible by your developers' IDEs.
```json
{
"prompts": {
"coreActions": {
"editCode": "You are a code modification assistant. Your task is to modify the provided code based on the user's instructions.\n\nRules:\n1. Return only the modified code, with no additional text or explanations.\n2. The first character of your response must be the first character of the code.\n3. The last character of your response must be the last character of the code.\n4. NEVER use triple backticks (```) or any other markdown formatting in your response.\n5. Do not use any code block indicators, syntax highlighting markers, or any other formatting characters.\n6. Present the code exactly as it would appear in a plain text editor, preserving all whitespace, indentation, and line breaks.\n7. Maintain the original code structure and only make changes as specified by the user's instructions.\n8. Ensure that the modified code is syntactically and semantically correct for the given programming language.\n9. Use consistent indentation and follow language-specific style guidelines.\n10. If the user's request cannot be translated into code changes, respond only with the word NULL (without quotes or any formatting).\n11. Do not include any comments or explanations within the code unless specifically requested.\n12. Assume that any necessary dependencies or libraries are already imported or available.\n\nIMPORTANT: Your response must NEVER begin or end with triple backticks, single backticks, or any other formatting characters.",
"fixCompileErrors": "I will provide you with a snippet of code that is causing a compilation error.\nYour task is to identify the potential causes of the compilation error(s) and propose code solutions to fix them.\nPlease approach this step by step, explaining your reasoning as you go.",
"generateCommitMessages": "Branch: {BRANCH_NAME}\nDate: {DATE_ISO_8601}\n\nWrite a short and descriptive git commit message for the following git diff.\nUse imperative mood, present tense, active voice and verbs.\nYour entire response will be passed directly into git commit.",
"generateNameLookups": "Provide five alternative names for a given function or method body. Your response should be a list of names, separated by commas, without any extra information.\n",
"reviewChanges": "You are an experienced software developer tasked with reviewing code changes and providing concise, valuable feedback. Your goal is to analyze the provided git diff and open files, then suggest logical and meaningful improvements if needed, focusing on brevity and specific code examples.\n\nFollow these steps to complete your review:\n\n1. Analyze the git diff and open files:\n Be concise and focus on the most important points. Include:\n - For each modified file:\n * Specific line numbers of changes\n * Brief description of changes, quoting specific lines of modified code\n * Change category (e.g., bug fix, feature addition, refactoring)\n * Purpose and potential impact\n * Any potential issues, risks, or bugs\n * Impact on code readability and maintainability\n * Potential impact on performance and scalability\n - Identification of any code smells or anti-patterns in the changes\n - Key relationships between changes in different files\n - Overall coherence and consistency of the changes\n - Any potential security concerns\n - For each change, consider and note its impact on the overall codebase\n\n2. Determine if improvements are needed:\n Based on your analysis, decide if any improvements are necessary. If so, provide your suggestions using the following format:\n\n ```{lang}\n // Your code suggestion here.\n ```\n\n Ensure your suggestions are:\n - Specific and actionable\n - Relevant to the changes in the git diff and the context of open files\n - Aligned with best practices in software development\n - Accompanied by brief explanations of their importance\n\n If no improvements are needed, briefly explain why the current changes are sufficient.\n\n3. Provide a short summary:\n - A brief overview of the changes reviewed\n - Main findings from your analysis\n - A concise list of key suggestions (if any), ordered by importance\n - Your overall assessment of the code changes\n\nRemember to keep your analysis, suggestions, and summary concise and to the point. Focus on providing specific code examples in your suggestions rather than verbose explanations."
},
"chatActions": [
{
"name": "Explain",
"instructions": "Your task is to provide a clear, concise explanation of what this code does. Focus on the main functionality and purpose of the code, avoiding unnecessary details. Explain any complex logic or algorithms if present.\n\nProvide your explanation in a few sentences, using simple language that a junior programmer could understand. If there are any notable best practices or potential improvements, briefly mention them at the end.\n\nHere's the code to analyze:\n{SELECTION}"
},
{
"name": "Refactor",
"instructions": "Your task is to improve the code's readability, efficiency, and maintainability without changing its functionality. Follow these steps:\n\n1. Analyze the following selected code:\n\n2. Identify areas for improvement, such as:\n - Simplifying complex logic\n - Removing redundant code\n - Improving naming conventions\n - Enhancing code structure\n\n3. Refactor the code, keeping these guidelines in mind:\n - Maintain the original functionality\n - Follow best practices for the programming language used\n - Prioritize readability and maintainability\n\nBe concise in your explanation, focusing on the most important improvements made.\n\nHere's the code to refactor:\n{SELECTION}"
}
],
"personas": [
{
"name": "CodeGPT Default",
"instructions": "You are an AI programming assistant.\nFollow the user's requirements carefully & to the letter.\nYour responses should be informative and logical.\nYou should always adhere to technical information.\nIf the user asks for code or technical questions, you must provide code suggestions and adhere to technical information.\nIf the question is related to a developer, you must respond with content related to a developer.\nFirst think step-by-step - describe your plan for what to build in pseudocode, written out in great detail.\nThen output the code in a single code block.\nMinimize any other prose.\nKeep your answers short and impersonal.\nUse Markdown formatting in your answers.\nAlways format code using Markdown code blocks, with the programming language specified at the start.\nAvoid wrapping the whole response in triple backticks.\nThe user works in an IDE built by JetBrains which has a concept for editors with open files, integrated unit test support, and output pane that shows the output of running the code as well as an integrated terminal.\nYou can only give one reply for each conversation turn."
Providing context enhances the AI's understanding and improves the relevance of its responses. ProxyAI enables the integration of context from various sources into chat prompts.
Use the `@` symbol to reference specific context, including files, directories, Git history, documentation, and web resources.
Refer to the [@ Symbols documentation](/context/symbols/overview) for detailed usage instructions.
## Chat Actions
ProxyAI includes built-in actions to help you with common coding tasks. Access them directly from the chat:
- **Find Bugs**: Let the AI scan your code for potential bugs and suggest fixes.
- **Write Tests**: Generate unit tests for your functions and classes quickly.
- **Explain**: Get clear explanations for selected code snippets or complex concepts.
- **Refactor**: Ask the AI to restructure your code for better readability or maintainability without changing what it does.
description: Modify code directly within the editor using natural language instructions.
---
# Inline Edit
Modify code segments directly in the editor using natural language instructions. ProxyAI applies your requested changes live without leaving your coding environment.
alt="Inline Edit process: Highlighting code, clicking the Edit Code icon, entering 'improve logging', submitting, and observing live code modification in the editor."
width="1200"
height="800"
className="nx-rounded-lg nx-my-4"
autoPlay
muted
loop
/>
To use Inline Edit:
* Select the code block you want to modify
* Click the **Edit Code** icon in the hover panel that appears
* Enter your instruction (e.g., "refactor to use async/await" or "add error handling")
* Press Enter to apply the changes directly to your code
### Keyboard Shortcuts
* **Initiate Inline Edit**: `Cmd+Shift+K` (macOS) or `Ctrl+Shift+K` (Windows/Linux)
ProxyAI helps you write code faster and more accurately. Get smart code suggestions and edits directly in your editor as you type.
## Autocomplete
Autocomplete feature focuses on providing real-time code completion suggestions as you type. It predicts and suggests code snippets near your cursor, offering single-line completions or generating entire functions or blocks of code based on the immediate context.
Next Edits feature reshapes the traditional autocomplete experience. It predicts your coding intentions across the entire file, offering context-aware suggestions and multi-line changes based on your recent modifications.
This feature is available only with ProxyAI Cloud and is not currently supported by any other provider. We are actively working to expand this functionality for a broader community.
### Enterprise Self-Hosting
For enterprises seeking advanced control and customization, a self-hosted version of Next Edits is available. Please [contact us](mailto:contact@codegpt.ee) for more information.
description: Install ProxyAI and start using AI in your IDE, whether using the public plugin or a private enterprise extension.
---
import { Steps, Tabs, Tab } from 'nextra/components'
import { Callout } from 'nextra/components'
# Getting Started
This guide explains how to install ProxyAI and begin using AI coding assistance inside your JetBrains IDE. The steps differ slightly depending on whether you are using the publicly available plugin or a private one provided by your organization.
Once installed, find the **ProxyAI Chat** tool window (usually on the right-hand side) or activate it via **Find Action** (`⌘/Ctrl + Shift + A` → search "ProxyAI Chat").
Upon first use, the public ProxyAI plugin defaults to using its own cloud service (ProxyAI Cloud) with basic model access. To unlock more powerful models or use different AI providers:
* Upgrade your ProxyAI Cloud plan ([see pricing](https://tryproxy.io/#pricing)).
* Configure the plugin to use an external provider (like OpenAI, Anthropic) with your own API key ([See Providers](/providers/overview)).
* Set up a connection to a local model using Ollama or Llama.cpp ([See Local Providers](/providers/local)).
</Tab>
<Tab>
Follow these instructions if your organization provides a private, customized version of ProxyAI (Custom Extension).
<Steps>
### Obtain the Plugin
The ProxyAI Custom Extension is **not available** on the public JetBrains Marketplace. Your organization (e.g., your IT department or development tools team) will provide you with the plugin (usually a `.zip`) and specific installation instructions.
### Install the Plugin from Disk
Typically, installation involves:
1. Open **Settings / Preferences → Plugins** in your JetBrains IDE.
2. Click the gear icon ⚙️ and select **Install Plugin from Disk...**.
3. Locate and select the `.zip` file provided by your organization.
4. Click **OK** or **Install**.
5. Restart your IDE when prompted to complete the installation.
*(Always consult your organization's internal documentation for precise installation steps, as they may differ slightly.)*
### Launch ProxyAI & Verify Configuration
After restarting, find the **ProxyAI Chat** tool window (usually on the right sidebar) or activate it via **Find Action** (`⌘/Ctrl + Shift + A` → search "ProxyAI Chat").
The Custom Extension is typically pre-configured by your administrator to connect to approved internal or private AI models using **[Remote Settings](/enterprise/remote-settings)**. It should connect automatically.
<Callout type="info">
**What are Remote Settings?** Your administrator defines standard configurations (like approved AI providers, models, and custom prompts) in a central file. The ProxyAI plugin fetches this file to ensure your setup aligns with organizational standards.
</Callout>
### Configure Remote Settings URL
In most cases, the Remote Settings URL will be pre-filled in your Custom Extension. However, if the plugin doesn't connect automatically or if instructed by your administrator:
1. Go to **Settings / Preferences → Tools → ProxyAI Enterprise → Remote Settings**.
2. Enter the **Remote settings URL** provided by your administrator into the field.
3. Click **Sync Settings**.
4. Review the detected configuration changes (if any) and click **Apply Changes**.
<Callout type="warning">
If you don't have the Remote Settings URL or encounter issues, contact your organization's internal support or the team that provided the plugin file.
</Callout>
*(For a detailed guide on how Remote Settings work and how to sync them, see [Applying Remote Settings in ProxyAI](/enterprise/remote-settings#applying-remote-settings-in-proxyai).)*
### Start Using AI Features
Once configured (either automatically or manually via Remote Settings sync), you can begin interacting with the chat or using features like autocomplete and AI commit messages. Your available models and features are determined by the central configuration managed by your administrator.
</Steps>
**Key Points for Custom Extension Users:**
* **Pre-configured:** Your extension is usually set up by your administrator to connect to specific, approved AI endpoints. You typically **do not** need to manually configure providers or API keys like users of the public plugin.
* **Remote Settings:** Your configuration is likely managed centrally via [Remote Settings](/enterprise/remote-settings). Changes made by your administrator may be automatically detected, prompting you to apply updates.
* **Internal Support:** For any issues related to installation, configuration, available models, or usage of the Custom Extension, please refer to your organization's internal support channels or documentation first.
description: An AI coding assistant for JetBrains IDEs, available as a public plugin or a private enterprise extension.
---
# Welcome to ProxyAI
ProxyAI is an intelligent coding assistant that seamlessly integrates with JetBrains IDEs including IntelliJ, PyCharm, and WebStorm. By providing context-aware code suggestions, automating routine tasks, and offering AI-powered assistance directly in your development environment, ProxyAI helps you code faster and more efficiently.
Choose between two flexible options:
1. **ProxyAI Public Plugin:** Available on the JetBrains Marketplace, this version is ideal for individual developers and teams. It offers flexibility by connecting to various cloud AI providers or local models.
2. **ProxyAI Private Plugin:** Designed for enterprises with specific security, compliance, or integration needs. This version is distributed privately, connects to organization-approved AI models (often self-hosted), and allows for centralized configuration management. [Learn more about Enterprise options](/enterprise/overview).
**Key Features**:
- Connects to **OpenAI, Anthropic, Google, Mistral, Inception**, and many other providers
- Supports next-edit suggestions, autocompletions, in-editor chat, fast apply, and much more
- First class citizen for offline/local development
- Deep integration with IDE stack (native look and feel)
- Bring your own API key or use ProxyAI Cloud (free tier included)
description: How ProxyAI handles your data and code.
---
# Privacy & Security
Your privacy and the security of your code are important to us. This page explains how ProxyAI handles your data.
**Your Code and Data Ownership**
Your code always belongs to you. We operate with Zero Data Retention for proprietary code by default, meaning we do not store it on our servers unless you explicitly opt in to specific improvement programs. By default, we do not use your code to train our AI models.
**How We Process Your Data**
Data handling varies depending on the feature you use:
* **Chat & Autocomplete:** When you use Chat or Autocomplete, we first route your input (messages or relevant code context) through our secure backend systems. Then, we send it to the AI model provider you selected (like OpenAI, Anthropic, or the default ProxyAI Cloud service). Responses are routed back through our system to you.
* **Next Edits:** For the Next Edits feature, we send relevant code snippets from your editor directly to an AI model that we host ourselves. These snippets are processed solely to generate suggestions.
**Third-Party Provider Policies**
When you configure ProxyAI to use third-party AI providers (like OpenAI or Anthropic directly with your own API key), their specific data handling policies apply to the data sent to them (including Chat and Autocomplete data). You should review their terms:
* **OpenAI:** May retain prompts for up to 30 days for trust and safety monitoring. Review [OpenAI’s enterprise privacy policy](https://openai.com/enterprise-privacy).
* **Anthropic:** May retain prompts if flagged during trust and safety reviews. Consult [Anthropic’s privacy policy](https://www.anthropic.com/legal/privacy).
**Usage Information and Product Improvement**
To improve ProxyAI, we collect basic, non-identifying telemetry data, such as the number of requests made for different features. We analyze this usage data to enhance the product and prioritize new features.
Separately, you have the option to help us improve our code assistance features. If you choose to opt-in to the setting "Help ProxyAI improve its products by sharing your code inputs and completions," we will collect code snippets you provide to **Next Edits**, along with the suggestions generated. We use this data solely to improve the quality and relevance of these specific features.
**Important:** This opt-in data sharing setting **is disabled by default** and **only applies to Next Edits**. We **never** collect your chat messages for product improvement purposes, regardless of your opt-in preference for code assistance features.
First, you'll need an Anthropic account. If you don't have one, [sign up here](https://console.anthropic.com/login).
### Get Your API Key
After signing up, create your API key on the [API Keys page](https://console.anthropic.com/settings/keys). This key is essential for authenticating your requests against the Anthropic API. If you already have a key, simply copy it to your clipboard.
### Configure the Plugin
Next, you'll need to configure the plugin to use the API key, version, and model:
- Navigate to the plugin's settings via **File > Settings/Preferences > Tools > ProxyAI > Providers > Anthropic**.
- Paste your API key into the designated field.
- The plugin automatically sets the `anthropic-version` value. If you want to use older versions, find more information [here](https://docs.anthropic.com/en/api/versioning).
- Select a model for messages and commands from the list below:
| Model | Latest 1P API model name |
| :----- | :----: |
| Claude 3 Opus | claude-3-opus-20240229
| Claude 3 Sonnet | claude-3-sonnet-20240229
| Claude 3 Haiku | claude-3-haiku-20240307
See the full list of available models [here](https://docs.anthropic.com/en/docs/models-overview#claude-3-a-new-generation-of-ai).
Code completions are currently unsupported by Azure OpenAI. To enable this feature, please
configure it manually using the Custom OpenAI provider.
</Callout>
## Getting Started
Follow these steps to get started:
import { Steps } from 'nextra/components'
<Steps>
### Get Your API Key
Azure OpenAI provides two methods for authentication. You can use either API Keys or Microsoft Entra ID.
To obtain your secret key, please refer to [this guide](https://learn.microsoft.com/en-us/azure/api-management/api-management-authenticate-authorize-azure-openai).
### Apply Your API Key
Next, configure the plugin to use the secret key you obtained, along with three additional fields.
- Navigate to the plugin's settings via **File > Settings/Preferences > Tools > ProxyAI > Providers > Azure**.
- Paste your API Key or Microsoft Entra ID into the designated field.
- Fill in the following additional fields:
- **Resource Name**: You can find this on your Azure Cognitive Services page under `Resource Management` → `Resource Management` → `Keys and Endpoints`. It is the first part of the URL provided to you for using the service: "https://**my-resource-name**.openai.azure.com/".
- **Deployment ID**: You can find this in the Azure AI Studio under `Management` → `Deployment`, in the `Deployment Name` column.
- **API Version**: Use the most recent, non-preview version.
API reference: https://platform.openai.com/docs/api-reference/chat
ProxyAI works with most OpenAI-compatible cloud providers, including Together.ai, Groq, Anyscale, and others, or you can set up a custom configuration.
## Getting Started
Before you begin, make sure you understand the basics of [REST API](https://www.redhat.com/en/topics/api/what-is-a-rest-api) principles.
import { Steps } from 'nextra/components'
<Steps>
### Chat Completions
In this example, we'll use Groq to power our messages and commands.
- Navigate to the plugin's settings via **File > Settings/Preferences > Tools > ProxyAI > Providers > Custom OpenAI**.
- Choose `Groq` from the Preset template dropdown.
Groq doesn't provide an LLM that supports fill-in-the-middle (FIM) completions, but you can use StarCoder 16B via the Fireworks API. ProxyAI includes a preset template for Fireworks—just get the API key and add it in the settings field.
Inception powers Mercury 2 and Mercury Edit 2, diffusion LLMs (dLLMs) tuned for fast, consistent code generation and multi-line edits. Unlike token-by-token generation, a dLLM refines drafts across many spans at once, which makes it especially strong at structural changes and predictive edits across files.
In the plugin, Inception uses:
- `mercury-2` as the general-purpose model for workflows such as Chat and Agent
- `mercury-edit-2` for Autocomplete and Next-Edit Suggestions
## Getting Started
Follow these steps to configure ProxyAI with your Inception API key:
import { Steps } from 'nextra/components'
<Steps>
### Create Your Account
If you don’t already have one, create an account at [Inception](https://platform.inceptionlabs.ai/.).
### Get Your API Key
From your Inception dashboard, create an API key and copy it to your clipboard.
### Apply Your API Key
Configure the ProxyAI plugin to use Inception:
- Go to **File > Settings/Preferences > Tools > ProxyAI > Providers > Inception**.
ProxyAI offers seamless integration with OpenAI, supporting all the latest models, including image input.
## Getting Started
Follow these steps to get started:
import { Steps } from 'nextra/components'
<Steps>
### Create Your Account
First, you'll need an OpenAI account. If you don't have one, [sign up here](https://platform.openai.com/signup).
### Get Your API Key
After signing up, create your API key on the [API Keys](https://platform.openai.com/api-keys) page. This key is necessary for authenticating your requests to the OpenAI API. If you already have a key, copy it to your clipboard.
### Apply Your API Key
Now, configure the plugin to use your API key:
- Navigate to the plugin's settings via **File > Settings/Preferences > Tools > ProxyAI > Providers > OpenAI**.
ProxyAI is the default cloud provider that powers this plugin. By creating a [free account](https://tryproxy.io/signin), you can access advanced AI models to enhance your coding experience.
## Getting Started
Follow these simple steps to get started:
import { Steps } from 'nextra/components'
<Steps>
### Create Your Free Account (optional)
ProxyAI offers two different tiers: Free, and Individual.
- **Free** - Token-limited access to ProxyAI features and selected managed models.
- **Individual** - Higher limits and access to the full managed ProxyAI catalog.
### Get Your API Key
You can find your API key on your [account page](https://tryproxy.io/account). Scroll down to "Your API Keys" and click the Copy icon next to your key. This key is essential for authenticating your requests with the ProxyAI API. If no key is provided, requests will default to the anonymous tier.
The main goal of `llama.cpp` is to run the LLaMA model using 4-bit integer quantization on a MacBook (locally). This is currently supported only on Linux and MacOS.
## Getting Started
import { Steps } from 'nextra/components'
<Steps>
### Select the Model
Choose the appropriate model based on your hardware capabilities from the provided list. Click `Download Model` to start the download. A progress bar will show the download progress.
### Start the Server
Once the model is downloaded, click `Start Server` to initiate the server. A status message will indicate that the server is starting.
### Apply Settings
With the server running, you can change settings, then click `Apply` or `OK` save your settings and start using the plugin.
Ollama enables you to run open-source large language models, such as Llama 3, on your local machine.
## Getting Started
Follow these steps to get started:
import { Steps } from 'nextra/components'
<Steps>
### Download the Client
First, download the Ollama client if you don't already have it. You can [download it here](https://ollama.com/download).
### Run Your Model
Open terminal and run the following command:
```
ollama run codellama
```
This command will download the model (if it doesn't already exist) and run it. This step is necessary before using the model in the plugin.
### Configure the Plugin
Next, connect Ollama with the plugin:
- Navigate to the plugin's settings via **File > Settings/Preferences > Tools > ProxyAI >
Providers > Ollama (Local)**.
- Click `Refresh Models` to sync all Ollama models with the plugin.
- Optionally, choose the appropriate FIM template for code completions. Before enabling code completions, ensure that the model supports fill-in-the-Middle (FIM).
Follow [this guide](https://meyer-laurent.com/run-deepseek-r1-locally-mac-mini-pycharm) to set up DeepSeek R1 locally on a Mac. This guide covers installing ProxyAI, configuring Ollama, and using a local Large Language Model for secure, AI-assisted coding without relying on public LLMs.
description: Learn which model catalogs the plugin currently exposes for ProxyAI, Inception, and the other built-in providers.
---
# Models
ProxyAI connects you to powerful large language models (LLMs) for chat and code generation.
## Selecting a Model
You can choose your preferred model in two ways:
### From the Chat Window:
Use the model dropdown in the Chat or Agent toolwindow to switch the active model for the current conversation. This is the fastest way to try a different model while you work.
alt="Selecting a model using the dropdown in the chat window"
width="1200"
height="800"
className="nx-rounded-lg nx-my-4"
autoPlay
muted
loop
/>
### From Settings:
Go to **Settings/Preferences > Tools > ProxyAI > Models** to manage model selection per feature. From this page, you can configure separate models for Chat, Agent, Autocomplete, Next-Edit Suggestions, and the other model-backed features, depending on which providers you have enabled.
## Built-In Model Catalogs
The tables below reflect the models currently exposed by ProxyAI Cloud. Models for `Ollama`, `llama.cpp`, `Custom OpenAI`, and other BYOK providers are determined by the configured provider and may change independently, so for those providers you should check the model picker in ProxyAI settings for the current list.
### Agent & Chat Models
| Model | Provider | Free | Pro |
|---|---|:---:|:---:|
| `auto` | Fireworks | ✅ | ✅ |
| `gpt-5.4` | OpenAI | | ✅ |
| `gpt-5.3-codex` | OpenAI | | ✅ |
| `gpt-5-mini` | OpenAI | ✅ | ✅ |
| `claude-opus-4-6` | Anthropic | | ✅ |
| `claude-sonnet-4-6` | Anthropic | | ✅ |
| `claude-haiku-4-5` | Anthropic | ✅ | ✅ |
| `gemini-3.1-pro-preview` | Google | | ✅ |
| `gemini-3-flash-preview` | Google | ✅ | ✅ |
`auto` is a dynamic selection and may change over time. ProxyAI chooses the model automatically based on the best quality-to-price ratio. It currently routes through Fireworks and uses `GLM-5`.
*Note: Model availability may change over time. When using your own API key, availability depends on the provider's offerings.*
## Context Windows
A model's context window defines how much information (measured in tokens) it can process at once, including both your inputs and the model's responses.
- Managed providers such as ProxyAI Cloud can apply product-level limits in addition to the underlying model limits.
- Bring-your-own-key providers follow the limits of the selected upstream model and API.
- Local and custom providers depend on the model and server configuration you run.
- Large files and long conversations still benefit from keeping context focused, even when a model advertises a large context window.
For complex or distinct tasks, regardless of the provider, starting a new chat session can improve performance and relevance.
## Model Hosting and Privacy
All **ProxyAI Cloud** models are hosted by their original providers (OpenAI, Anthropic, etc.), trusted partners, or ProxyAI directly, primarily on US-based infrastructure.
When connecting to other providers or using local models, hosting location and privacy considerations follow those specific services or your local environment settings.
description: Learn how ProxyAI connects to different AI services (providers) to power its features.
---
# Provider Overview
ProxyAI connects to different AI services (providers) to power its features. Your choice of provider determines which Large Language Model (LLM) works behind the scenes in your IDE.
## ProxyAI Cloud
Our cloud service offers the simplest way to get started. You'll get access to carefully selected powerful AI models, including some exclusive options. Setup is minimal - just sign up and add an API key.
## Other Cloud Providers
Connect directly to major AI platforms like OpenAI, Anthropic, or Google. This gives you flexibility to use specific models from these services with your own API keys and accounts.
## Local Models (Ollama, Llama.cpp)
Run LLMs directly on your machine using tools like Ollama or Llama.cpp. Your code and prompts never leave your computer, giving you complete privacy and control. This works well for offline use or sensitive data, but requires more setup and a capable computer.
## Custom OpenAI Compatible
Connect to services that implement the OpenAI API. This works with alternative cloud providers (Groq, Anyscale, Together AI) or private LLM deployments that follow the OpenAI API structure.
Find detailed setup instructions for each provider type in the following sections.
# Deploy Deepseek R1 on a RunPod and use it in PyCharm
*By Laurent Meyer*
---
Deploy DeepSeek-R1 on Runpod Serverless with Docker & vLLM—run your own private local LLM that processes RAG data, auto-scales, and shuts down when idle.
[Read the full article →](https://meyer-laurent.com/deploying-deepseek-r1-on-runpod-serverless-and-use-it-in-pycharm)
# Run Deepseek R1 locally on a Mac Mini in PyCharm
*By Laurent Meyer*
---
Discover how to enhance your development workflow and protect proprietary code by setting up DeepSeek R1 locally on a Mac. This guide covers installing ProxyAI, configuring Ollama, and using a local Large Language Model for secure, AI-assisted coding without relying on public LLMs.
[Read the full article →](https://meyer-laurent.com/run-deepseek-r1-locally-mac-mini-pycharm)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}