* fix(streaming): #1211 greedy strip omniModel tags to prevent literal \n\n artifacts - Changed regex quantifier from ? to * in combo.ts, comboAgentMiddleware.ts, and contextHandoff.ts to greedily strip all JSON-escaped newline sequences surrounding <omniModel> tags in SSE streaming chunks - Added \r to the character class for cross-platform robustness - Fixed Playwright strict-mode violation in combo-unification.spec.ts - Bumped OpenAPI version and CHANGELOG to 3.6.6 * fix: 3 bugs found during issue triage (#1175, #1187/#1218, #1202) - fix(gemini): strip VS Code JSON Schema extensions from tool schemas (#1175) Add enumDescriptions, markdownDescription, markdownEnumDescriptions, enumItemLabels and tags to UNSUPPORTED_SCHEMA_CONSTRAINTS so the Gemini sanitizer removes them before forwarding. GitHub Copilot injects these non-standard fields into tool definitions, causing Gemini to reject with 'Unknown name enumDescriptions at functionDeclarations[n].parameters'. - fix(health-check): unwrap proxy config object before passing to getAccessToken (#1187 #1218) resolveProxyForConnection() returns { proxy, level, levelId } but the health check loop was passing the full wrapper to getAccessToken(), which expects the inner config object (.host, .port etc). The proxy dispatcher validated .host on the wrapper (undefined) and threw 'Context proxy host is required', silently marking every connection as unhealthy every sweep. Fix mirrors the pattern already used in chatHelpers.ts: proxyResult?.proxy || null. - fix(ui): debounce models.dev sync interval slider to save only on release (#1202) The slider's onChange fired updateInterval() on every drag tick, sending a PATCH per pixel of movement. Rapid API responses overwrote UI state mid-drag. Introduce draftIntervalHours for smooth visual feedback; the PATCH fires on onMouseUp / onBlur once the user releases the control. * fix(providers): update Xiaomi MiMo token-plan endpoints (#1238) Integrated into release/v3.6.6 * fix(cc-compatible): trim beta flags and preserve cache passthrough (#1230) Integrated into release/v3.6.6 * feat(memory+skills): full-featured memory & skills systems with tests (#1228) Integrated into release/v3.6.6 * fix: forward client x-initiator header to GitHub Copilot upstream (#1227) Integrated into release/v3.6.6 * feat(bailian-quota): add Alibaba Coding Plan quota monitoring (#1235) * fix: resolve v3.6.6 backlog bugs (#1206, #1211, #1220, #1231) - fix(core): #1206 inject startup guard against app/ and src/app/ conflict - fix(health): #1220 add HEALTHCHECK_STAGGER_MS to prevent token refresh bursting - fix(proxy): #1231 prioritize HTTP 429 over quota body heuristics - fix(sse): #1211 strip leading double-newlines in responses API stream * fix(tests): resolve memory migration and skills route pagination bugs from PR overlaps * docs: Update CHANGELOG.md with v3.6.6 features (#1182, #1165, #1177) * chore(release): bump version to 3.6.6 Update package versions for the electron app and open-sse package. Sync llm.txt metadata and feature headings with the 3.6.6 release. * feat(core): harden outbound provider calls and add cooldown retries Add guarded outbound fetch helpers with private/local URL blocking, controlled retries, timeout normalization, and route-level status propagation for provider validation and model discovery. Introduce cooldown-aware chat retries with configurable requestRetry and maxRetryIntervalSec settings, model-scoped cooldown responses, and improved rate-limit learning from headers and error bodies so short upstream lockouts can recover automatically. Also align Antigravity and Codex header handling, require API keys for Pollinations, validate web runtime env at startup, restore sanitized Gemini tool names in translated responses, and inject a synthetic Claude text block when upstream SSE completes empty. * feat(models): add glmt preset and hybrid token counting Introduce GLM Thinking as a first-class provider preset with shared GLM model metadata, pricing, usage sync, dashboard support, and provider request defaults for higher token budgets and longer timeouts. Use provider-side /messages/count_tokens when a Claude-compatible upstream supports it, while preserving estimated fallback behavior for missing models, missing credentials, and upstream failures. Also add startup seeding for default model aliases and normalize common cross-proxy model dialects so canonical slashful model ids do not get misrouted during resolution. * feat(api): add sync tokens and v1 websocket bridge Add dedicated sync token storage, issuance, revocation, and bundle download routes backed by stable config bundle versioning and ETag support. Expose the v1 websocket handshake route and custom Next server bridge so OpenAI-compatible websocket traffic can be upgraded and proxied through the dashboard and API bridge. Expand compliance auditing with structured metadata, pagination, request context, auth and provider credential events, and SSRF-blocked validation logging. * docs: Update all documentation for v3.6.6 - CHANGELOG: Add WebSocket bridge, GLM Thinking preset, safe outbound fetch/SSRF guard, cooldown-aware retries, compliance audit v2, model alias seeding, and all Internal Improvements for the 3 new commits - README: Expand v3.6.x highlights table with 10 new features; add SafeOutboundFetch, CooldownAwareRetry, SSRF guard, TPS metric, sync tokens, WebSocket bridge to Resilience/Observability/Deployment tables - ARCHITECTURE: Bump date; add new modules to executive summary, API routes, SSE core services, Auth/Security section; add SSRF/Outbound guard failure mode (section 6); expand module mapping - ENVIRONMENT: Add OMNIROUTE_CRYPT_KEY/OMNIROUTE_API_KEY_BASE64 legacy aliases, OUTBOUND_SSRF_GUARD_ENABLED, CODEX_CLIENT_VERSION, and REQUEST_RETRY/MAX_RETRY_INTERVAL_SEC cooldown retry settings - FEATURES: Add 6 new feature sections — V1 WebSocket Bridge, Sync Tokens & Config Bundle, GLM Thinking Preset, Safe Outbound Fetch & SSRF Guard, Cooldown-Aware Retries, Compliance Audit v2 * fix: use api64 for proxy test (#1255) Integrated into release/v3.6.6 — IPv6 proxy test fix * fix(page): update custom models section to include all providers #1200 (#1256) Integrated into release/v3.6.6 — Gemini custom model picker fix * fix: provide default client_id fallbacks to prevent broken OAuth requests (#1246) Integrated into release/v3.6.6 — OAuth client_id default fallbacks * fix: translate max_tokens/max_completion_tokens → max_output_tokens in Chat→Responses translator (#1245) Integrated into release/v3.6.6 — max_tokens → max_output_tokens Responses API translation + unit tests * feat(oauth): support cursor-agent CLI as Cursor credential source (#1258) Integrated into release/v3.6.6 — cursor-agent CLI credential source support * fix(cc-compatible): restore upstream SSE and correct stream/combo timeout behavior (#1257) Integrated into release/v3.6.6 — CC-compatible upstream SSE restore + stream timeout fix + README table repair * fix(cli-tools): resolve API key resolution and model mapping bugs in CLI tools (#1263) Integrated into release/v3.6.6 * feat(cli-tools): add Qwen Code CLI integration (#1266) Integrated into release/v3.6.6 * fix(i18n): add missing zh-CN translations and fix logger imports (#1269) Integrated into release/v3.6.6 * fix(i18n): add Chinese i18n support to dashboard components (#1274) Integrated into release/v3.6.6 * feat: update Pollinations to require API key, remove free tier flag (#1177) * feat: friendly error messages for crypto/encryption failures (#1165) * feat: add TPS (tokens per second) metric column to request logs (#1182) * feat: merge custom/imported models into filter list for all providers (#1191) * feat(fallback): Fix provider-profile-driven lockouts (#1267) This integrates rdself's unify-provider-profile-locks PR manually to handle structural conflicts. * fix(claude): proper Anthropic SDK integration (#1271) * fix(healthcheck): use correct proxy wrapper format for getAccessToken (#1272) * chore(release): v3.6.6 — skills registry stability fix + final integration * fix(auth): harden bootstrap auth and memory dashboard behavior Restrict unauthenticated writes to /api/settings/require-login to the initial bootstrap window while keeping read-only checks public. This prevents post-setup config changes without blocking first-run login setup, and the onboarding flow now logs in immediately after setting the password. Restore memory API filtering and pagination behavior by supporting q searches, honoring offset-based requests, and avoiding unrelated fallback results when FTS misses. Update dashboard stats fallback to use the response totals consistently. Package the MCP server with explicit file entries and add regression tests for bootstrap auth and memory route behavior * fix(codex): remove max_output_tokens from body for compatibility * chore(release): v3.6.6 — include PR 1274 fixes in changelog * chore: exclude additional build artifacts and internal directories from npm package distribution * fix: update Gemini OAuth test to match registry defaults + codex UI improvements * fix: restore .mjs refs for scripts/ in test imports after ts migration * fix: restore next.config.mjs ref in dev-origins test * fix: implement db migration safety checks and codex config format * fix: disable mass-migration abort during unit tests based on auto-backup flag * fix: update script regex in auto-update tests to use .mjs * feat: Add Perplexity Web (Session) provider (#1289) Integrated into release/v3.6.6 * fix(cli): resolve codex routing config parsing, standardize select model button positioning, and clarify oauth documentation * docs(changelog): record recent cli, provider, and test updates Document the latest fixes for Codex routing configuration parsing and Lobehub provider icon fallback behavior. Add the note that the remaining JavaScript test files were migrated to TypeScript ES modules to reflect the completed test stack transition. * chore(release): merge #1286 minor improvements manually to avoid testing conflict * chore(test): rename perplexity-web.test.mjs to .ts to maintain 100% TS codebase * chore(docs): update CHANGELOG.md for perplexity-web provider * fix(security): resolve CodeQL incomplete URL substring sanitization via URL parsing in test mocks * fix: integrate compressContext() into chatCore.ts request pipeline Proactively compress oversized contexts before sending to upstream providers, preventing context_length_exceeded errors. Compression triggers at 85% of model's context limit using the existing 3-layer compressContext() function. - Import compressContext, estimateTokens, getTokenLimit from contextManager - Add compression check after translation, before executor dispatch - Estimate tokens and compare against 85% threshold of model's context limit - Apply 3-layer compression (trim tools, compress thinking, purify history) - Log compression events with before/after token counts and layers applied - Audit compression events for observability - Add unit tests verifying integration behavior Closes #1290 * fix(tests): align reasoning expectations with GLM thinking structure * fix: prevent orphaned tool_result messages in purifyHistory() When purifyHistory() drops oldest messages to fit context window, it can split tool_use/tool_result pairs — keeping the tool_result but dropping the tool_use that initiated it. This causes upstream providers to reject the request with format errors. Add fixToolPairs() that runs after each purification pass to remove: - OpenAI format: orphaned role='tool' messages without matching tool_calls ID - Claude format: orphaned tool_result content blocks without matching tool_use ID Closes #1291 * fix(tests): supply tool_use in mock so it is not dropped * chore: convert remaining test to TypeScript * fix(tests): restore compatibility with compressContext threshold test after tsx migration * docs: finalize v3.6.6 release documentation * fix(core): finalize provider removal, type issues, and codex API key config * fix(dashboard): render Web/Cookie, Search, Audio provider sections and fix TypeScript errors * fix: increase MCP web_search timeout to 60s (#1278) * fix: route combo testing properly for embedding models (#1260) * fix: accumulate excluded accounts in combo fallback loop (#1233) * fix: strip leading whitespace and newlines from first streaming chunk (#1211) * docs: clarify VPS and Docker settings for OAuth credentials (#1204) * fix: return real retry-after for pipeline gates (#1301) Integrated into release/v3.6.6 — returns real Retry-After values from pipeline gates * feat: streaming semantic cache, Cursor auto-version detection, and call-log enhancements (#1296) Integrated into release/v3.6.6 — streaming semantic cache, Cursor auto-version detection, call-log cache_source tracking * feat(api): support more OpenAI types (image, embeddings, audio-transcriptions, audio-speech) (#1297) Integrated into release/v3.6.6 — adds embeddings, audio-transcriptions, audio-speech, and images-generations support for custom OpenAI-compatible providers, plus Pollinations image registry * deps: bump hono from 4.12.12 to 4.12.14 (#1302) Integrated into release/v3.6.6 * deps: bump hono from 4.12.12 to 4.12.14 (#1306) Integrated into release/v3.6.6 * chore: stabilization fixes for v3.6.6 (#1298, #1254, #59, CI) * fix(providers): match correct endpoint for Xiaomi MiMo, strip routing prefix for custom openai endpoints (#1303, #1261) * feat(storage): add database backup cleanup controls * chore(release): v3.6.6 — Final Stabilization Push * Backport call log storage refactor to release/v3.6.6 (#1307) Integrated into release/v3.6.6 * deps: update dompurify to 3.4.0 to resolve CVE-XYZ (#60) * test: disable sqlite auto backup in CI to resolve E2E timeout (#24481475058) * chore(docs): sync CHANGELOG for v3.6.6 with missing features and fixes * chore(release): prep v3.6.6 infrastructure and type safety fixes - Migrated legacy .mjs scripts to .ts (bin, prepublish, policies) - Resolved pre-commit strict lint (t11 budget) errors in combo.ts - Explicitly typed all TS bindings in pack-artifact policies - Updated package.json commands to run Node via tsx/esm internally - Hardened CI/CD with explicit node version 22.22.2 checks - Completed stage validations for v3.6.6 final release * chore: fix TS build errors and e2e timeouts in CI - Migrate nodeRuntimeSupport to TS interfaces avoiding implicit any - Increase visibility timeouts in skills-marketplace E2E test to 15s to bypass CI flakiness - Complete migration of .mjs scripts to .ts ensuring type safety * chore(release): sync package version 3.6.6 across workspaces * test(e2e): universally increase UI component visibility timeouts from 5s to 15s to bypass CI starvation * chore(build): inject baseUrl, paths, and types:node into MITM tsconfig within prepublish hook to fix missing types in CI check --------- Co-authored-by: diegosouzapw <diegosouzapw@users.noreply.github.com> Co-authored-by: Jack <5443152+hijak@users.noreply.github.com> Co-authored-by: Randi <55005611+rdself@users.noreply.github.com> Co-authored-by: Paijo <14921983+oyi77@users.noreply.github.com> Co-authored-by: Samuel Cedric <ceds.sam@gmail.com> Co-authored-by: Max Garmash <max@37bytes.com> Co-authored-by: Markus Hartung <mail@hartmark.se> Co-authored-by: Gi99lin <74502520+Gi99lin@users.noreply.github.com> Co-authored-by: Payne <baboialex95@gmail.com> Co-authored-by: Benson K B <bensonkbmca@gmail.com> Co-authored-by: clousky2020 <33016567+clousky2020@users.noreply.github.com> Co-authored-by: Ravi Tharuma <25951435+RaviTharuma@users.noreply.github.com> Co-authored-by: oyi77 <oyi77@users.noreply.github.com> Co-authored-by: Hdsje <vovan877@gmail.com> Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com> Co-authored-by: xiaoge1688 <moyekongling@gmail.com>
14 KiB
OmniRoute — Dashboard Features Gallery
🌐 Languages: 🇺🇸 English | 🇧🇷 Português (Brasil) | 🇪🇸 Español | 🇫🇷 Français | 🇮🇹 Italiano | 🇷🇺 Русский | 🇨🇳 中文 (简体) | 🇩🇪 Deutsch | 🇮🇳 हिन्दी | 🇹🇭 ไทย | 🇺🇦 Українська | 🇸🇦 العربية | 🇯🇵 日本語 | 🇻🇳 Tiếng Việt | 🇧🇬 Български | 🇩🇰 Dansk | 🇫🇮 Suomi | 🇮🇱 עברית | 🇭🇺 Magyar | 🇮🇩 Bahasa Indonesia | 🇰🇷 한국어 | 🇲🇾 Bahasa Melayu | 🇳🇱 Nederlands | 🇳🇴 Norsk | 🇵🇹 Português (Portugal) | 🇷🇴 Română | 🇵🇱 Polski | 🇸🇰 Slovenčina | 🇸🇪 Svenska | 🇵🇭 Filipino | 🇨🇿 Čeština
Visual guide to every section of the OmniRoute dashboard.
🔌 Providers
Manage AI provider connections: OAuth providers (Claude Code, Codex, Gemini CLI), API key providers (Groq, DeepSeek, OpenRouter), and free providers (Qoder, Qwen, Kiro). Kiro accounts include credit balance tracking — remaining credits, total allowance, and renewal date visible in Dashboard → Usage.

🎨 Combos
Create model routing combos with 13 strategies: priority, weighted, round-robin, random, least-used, cost-optimized, strict-random, auto, fill-first, p2c, lkgp, context-optimized, and context-relay. Each combo chains multiple models with automatic fallback and includes quick templates and readiness checks.
Recent combo improvements:
- Structured combo builder — create each step by selecting provider, model, and exact account/connection
- Repeated provider support — reuse the same provider many times in one combo as long as the
(provider, model, connection)tuple is unique - Combo target health — analytics and health surfaces now distinguish individual combo targets/steps instead of collapsing everything into model strings
- Composite tier ordering —
defaultTier -> fallbackTiernow influences runtime execution/fallback order for top-level combo steps
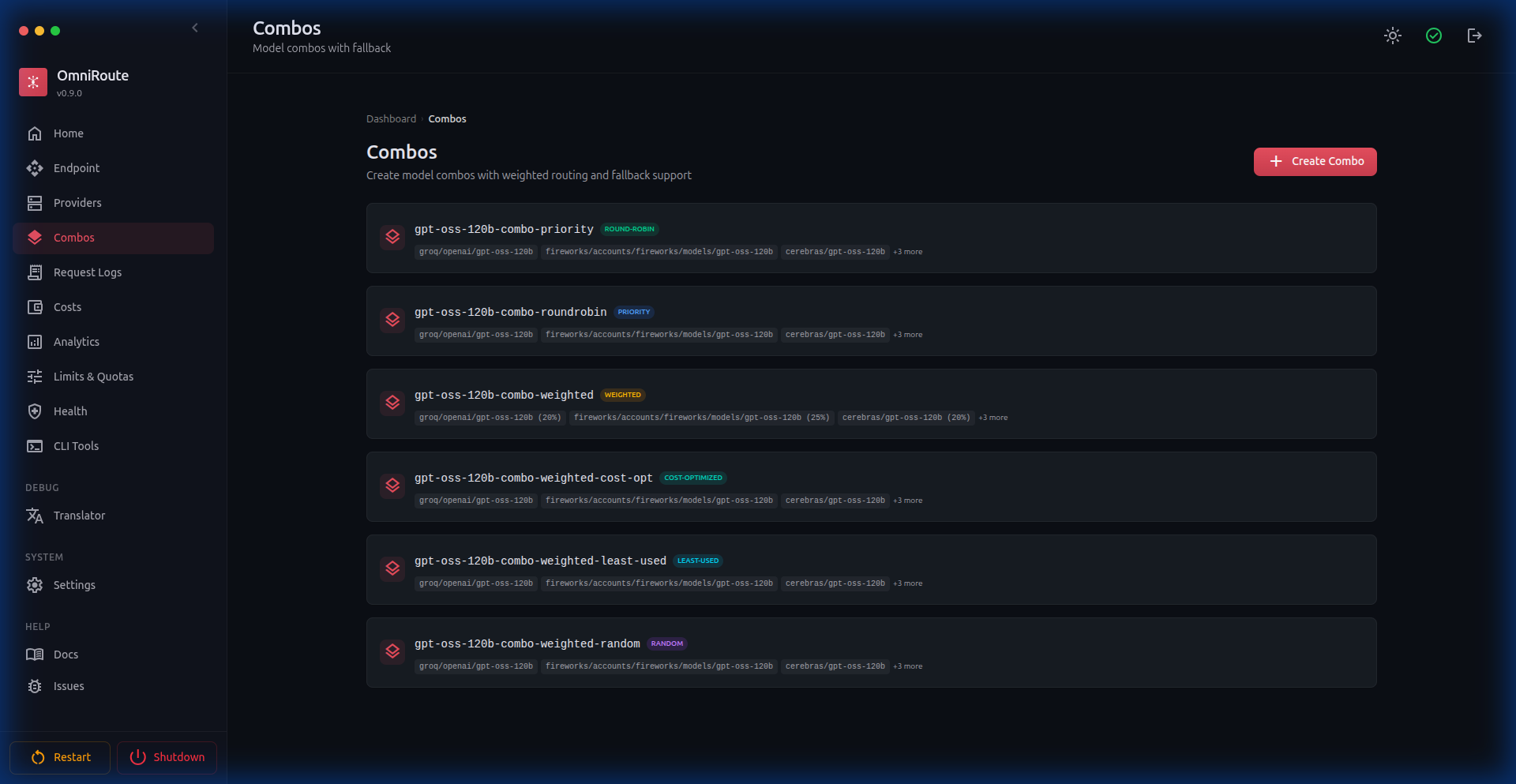
📊 Analytics
Comprehensive usage analytics with token consumption, cost estimates, activity heatmaps, weekly distribution charts, and per-provider breakdowns.
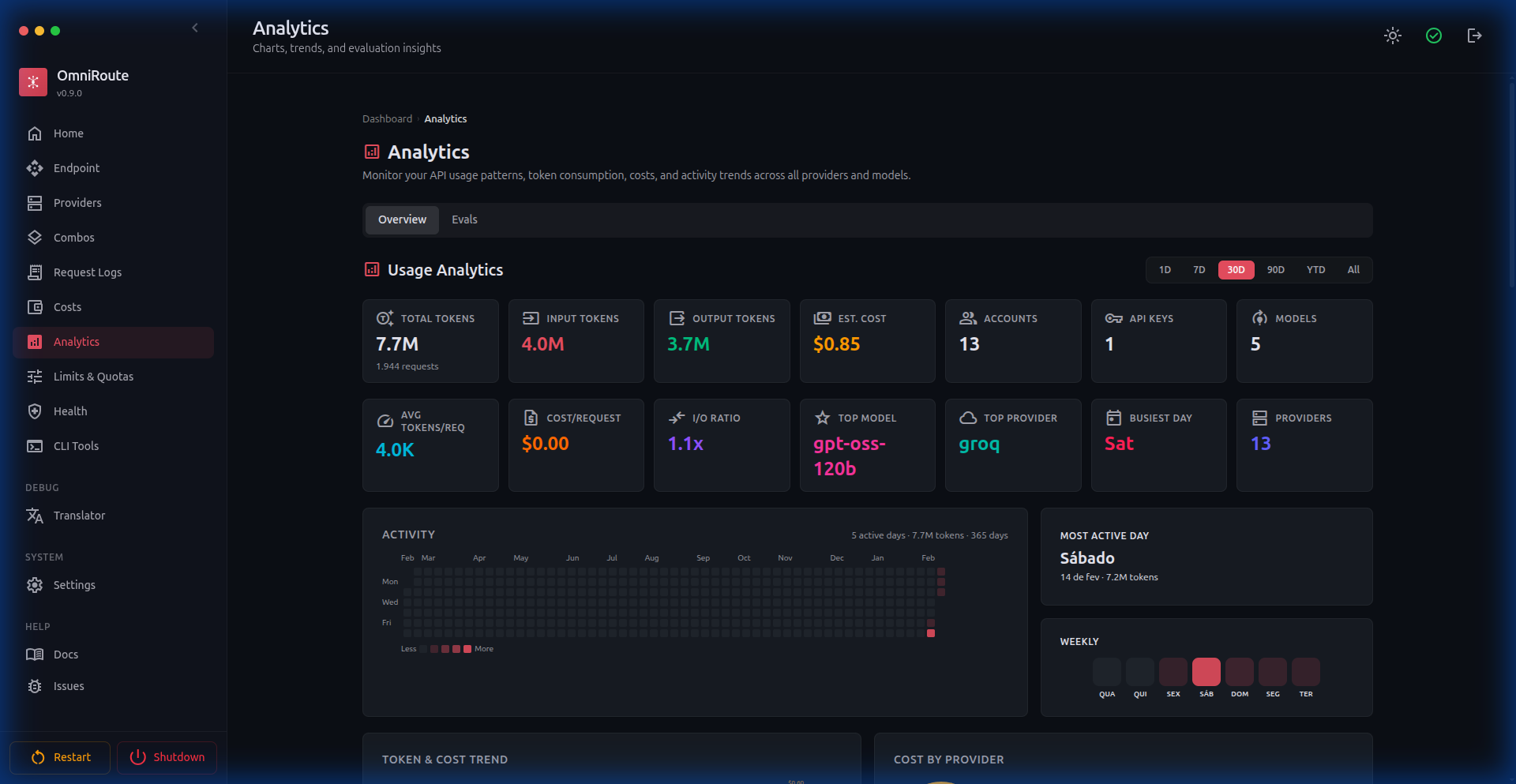
🏥 System Health
Real-time monitoring: uptime, memory, version, latency percentiles (p50/p95/p99), cache statistics, provider circuit breaker states, active quota-monitored sessions, and combo target health.
🔧 Translator Playground
Four modes for debugging API translations: Playground (format converter), Chat Tester (live requests), Test Bench (batch tests), and Live Monitor (real-time stream).

🎮 Model Playground (v2.0.9+)
Test any model directly from the dashboard. Select provider, model, and endpoint, write prompts with Monaco Editor, stream responses in real-time, abort mid-stream, and view timing metrics.
🎨 Themes (v2.0.5+)
Customizable color themes for the entire dashboard. Choose from 7 preset colors (Coral, Blue, Red, Green, Violet, Orange, Cyan) or create a custom theme by picking any hex color. Supports light, dark, and system mode.
⚙️ Settings
Comprehensive settings panel with tabs:
- General — System storage, backup management (export/import database)
- Appearance — Theme selector (dark/light/system), color theme presets and custom colors, health log visibility, sidebar item visibility controls
- Security — API endpoint protection, custom provider blocking, IP filtering, session info
- Routing — Model aliases, background task degradation
- Resilience — Rate limit persistence, circuit breaker tuning, auto-disable banned accounts, provider expiration monitoring, Context Relay handoff threshold and summary model configuration
- Advanced — Configuration overrides, configuration audit trail, fallback degradation mode

🔧 CLI Tools
One-click configuration for AI coding tools: Claude Code, Codex CLI, Gemini CLI, OpenClaw, Kilo Code, Antigravity, Cline, Continue, Cursor, and Factory Droid. Features automated config apply/reset, connection profiles, and model mapping.

🤖 CLI Agents (v2.0.11+)
Dashboard for discovering and managing CLI agents. Shows a grid of 14 built-in agents (Codex, Claude, Goose, Gemini CLI, OpenClaw, Aider, OpenCode, Cline, Qwen Code, ForgeCode, Amazon Q, Open Interpreter, Cursor CLI, Warp) with:
- Installation status — Installed / Not Found with version detection
- Protocol badges — stdio, HTTP, etc.
- Custom agents — Register any CLI tool via form (name, binary, version command, spawn args)
- CLI Fingerprint Matching — Per-provider toggle to match native CLI request signatures, reducing ban risk while preserving proxy IP
🔗 Context Relay (v3.5.5+)
A combo strategy that preserves session continuity when account rotation happens mid-conversation. Before the active account is exhausted, OmniRoute generates a structured handoff summary in the background. After the next request resolves to a different account, the summary is injected as a system message so the new account continues with full context.
Configurable via combo-level or global settings:
- Handoff Threshold — Quota usage percentage that triggers summary generation (default 85%)
- Max Messages For Summary — How much recent history to condense
- Summary Model — Optional override model for generating the handoff summary
Currently supports Codex account rotation. See Context Relay documentation.
🛡️ Proxy Hardening (v3.5.5+)
Comprehensive proxy configuration enforcement across the entire request pipeline:
- Token Health Check — Background OAuth refresh now resolves proxy config per connection, preventing failures in proxy-required environments
- API Key Validation — Provider key validation (
POST /api/providers/validate) routes throughrunWithProxyContext, honoring provider-level and global proxy settings - undici Dispatcher Fix — Proxy dispatchers use undici's own fetch implementation instead of Node's built-in fetch, resolving
invalid onRequestStart methoderrors on Node.js 22 - Node.js Version Detection — Login page proactively detects incompatible Node.js versions (24+) and displays a warning banner with instructions to use Node 22 LTS
📧 Email Privacy Masking (v3.5.6+)
OAuth account emails are now masked in the provider dashboard (e.g. di*****@g****.com) to prevent accidental exposure when sharing screenshots or recording demos. The full email address remains accessible via hover tooltip (title attribute).
👁️ Model Visibility Toggle (v3.5.6+)
The provider page model list now includes:
- Real-time search/filter bar — Quickly find specific models
- Per-model visibility toggle (👁 icon) — Hidden models are grayed out and excluded from the
/v1/modelscatalog - Active-count badge (
N/M active) — Shows at a glance how many models are enabled vs total
🔧 OAuth Env Repair (v3.6.1+)
One-click "Repair env" action for OAuth providers that restores missing environment variables and fixes broken auth state. Accessible from Dashboard → Providers → [OAuth Provider] → Repair env. Automatically detects and repairs:
- Missing OAuth client credentials
- Corrupted env file entries
- Backup path sanitization
🗑️ Uninstall / Full Uninstall (v3.6.2+)
Clean removal scripts for all installation methods:
| Command | Action |
|---|---|
npm run uninstall |
Removes the system app but keeps your DB and configurations in ~/.omniroute. |
npm run uninstall:full |
Removes the app AND permanently erases all configurations, keys, and databases. |
🖼️ Media (v2.0.3+)
Generate images, videos, and music from the dashboard. Supports OpenAI, xAI, Together, Hyperbolic, SD WebUI, ComfyUI, AnimateDiff, Stable Audio Open, and MusicGen.
📝 Request Logs
Real-time request logging with filtering by provider, model, account, and API key. Shows status codes, token usage, latency, and response details.

🌐 API Endpoint
Your unified API endpoint with capability breakdown: Chat Completions, Responses API, Embeddings, Image Generation, Reranking, Audio Transcription, Text-to-Speech, Moderations, and registered API keys. Cloudflare Quick Tunnel integration and cloud proxy support for remote access.

🔑 API Key Management
Create, scope, and revoke API keys. Each key can be restricted to specific models/providers with full access or read-only permissions. Visual key management with usage tracking.
📋 Audit Log
Administrative action tracking with filtering by action type, actor, target, IP address, and timestamp. Full security event history.
🖥️ Desktop Application
Native Electron desktop app for Windows, macOS, and Linux. Run OmniRoute as a standalone application with system tray integration, offline support, auto-update, and one-click install.
Key features:
- Server readiness polling (no blank screen on cold start)
- System tray with port management
- Content Security Policy
- Single-instance lock
- Auto-update on restart
- Platform-conditional UI (macOS traffic lights, Windows/Linux default titlebar)
- Hardened Electron build packaging — symlinked
node_modulesin the standalone bundle is detected and rejected before packaging, preventing runtime dependency on the build machine (v2.5.5+) - Graceful shutdown — Electron
before-quitshuts down Next.js cleanly, preventing SQLite WAL database locks (v3.6.2+)
📖 See electron/README.md for full documentation.
🌐 V1 WebSocket Bridge (v3.6.6+)
OmniRoute now supports OpenAI-compatible WebSocket clients via the /v1/ws upgrade endpoint. The custom scripts/v1-ws-bridge.mjs server wraps Next.js and upgrades WS connections to full bidirectional streaming sessions. Authentication uses the same API key or session cookie as HTTP requests.
Key behaviours:
- WS upgrade validated by
src/lib/ws/handshake.tsbefore the connection is established - Streams terminated cleanly on session close or upstream error
- Works alongside the existing HTTP+SSE streaming path simultaneously
🔑 Sync Tokens & Config Bundle (v3.6.6+)
Multi-device and external operator access is now possible via scoped sync tokens:
POST /api/sync/tokens— Issue a new sync token (scoped, with optional expiry)DELETE /api/sync/tokens/:id— Revoke a tokenGET /api/sync/bundle— Download a versioned, ETag-keyed JSON snapshot of all non-sensitive settings (passwords redacted)
The config bundle is built by src/lib/sync/bundle.ts. Consumers compare the ETag response header to detect changes without re-downloading the full payload.
🧠 GLM Thinking Preset (v3.6.6+)
GLM Thinking (glmt) is now a registered first-class provider: 65 536 max output tokens, 24 576 thinking budget, 900 s default timeout, Claude-compatible API format, and shared usage sync with the GLM family.
Hybrid token counting also lands in v3.6.6: when a Claude-compatible provider exposes /messages/count_tokens, OmniRoute calls it before large requests with graceful estimation fallback.
🛡️ Safe Outbound Fetch & SSRF Guard (v3.6.6+)
All provider validation and model discovery calls now go through a two-layer outbound guard:
- URL guard (
src/shared/network/outboundUrlGuard.ts) — Blocks private/loopback/link-local IP ranges before the socket is opened. - Safe fetch wrapper (
src/shared/network/safeOutboundFetch.ts) — Applies the URL guard, normalises timeouts, and retries transient errors with exponential backoff.
Guard violations surface as HTTP 422 (URL_GUARD_BLOCKED) and are written to the compliance audit log via providerAudit.ts.
🔄 Cooldown-Aware Retries (v3.6.6+)
Chat requests now automatically retry when an upstream provider returns a model-scoped cooldown. Configurable via REQUEST_RETRY (default: 2) and MAX_RETRY_INTERVAL_SEC (default: 30 s). Rate-limit header learning improved across x-ratelimit-reset-requests, x-ratelimit-reset-tokens, and Retry-After — per-model cooldown state is visible in the Resilience dashboard.
📋 Compliance Audit v2 (v3.6.6+)
The audit log has been expanded with cursor-based pagination, request context enrichment (request ID, user agent, IP), structured auth events, provider CRUD events with diff context, and SSRF-blocked validation logging. New events emitted by src/lib/compliance/providerAudit.ts.