mirror of
https://github.com/QwenLM/qwen-code.git
synced 2026-04-30 12:40:44 +00:00
resolve comment
This commit is contained in:
commit
e4e21bb6b7
93 changed files with 3360 additions and 1604 deletions
|
|
@ -1,13 +1,12 @@
|
|||
# Authentication
|
||||
|
||||
Qwen Code supports two authentication methods. Pick the one that matches how you want to run the CLI:
|
||||
Qwen Code supports three authentication methods. Pick the one that matches how you want to run the CLI:
|
||||
|
||||
- **Qwen OAuth (recommended)**: sign in with your `qwen.ai` account in a browser.
|
||||
- **API-KEY**: use an API key to connect to any supported provider. More flexible — supports OpenAI, Anthropic, Google GenAI, Alibaba Cloud Bailian, and other compatible endpoints.
|
||||
- **Qwen OAuth**: sign in with your `qwen.ai` account in a browser. Free with a daily quota.
|
||||
- **Alibaba Cloud Coding Plan**: use an API key from Alibaba Cloud. Paid subscription with diverse model options and higher quotas.
|
||||
- **API Key**: bring your own API key. Flexible to your own needs — supports OpenAI, Anthropic, Gemini, and other compatible endpoints.
|
||||
|
||||
|
||||
|
||||
## 👍 Option 1: Qwen OAuth (recommended & free)
|
||||
## Option 1: Qwen OAuth (Free)
|
||||
|
||||
Use this if you want the simplest setup and you're using Qwen models.
|
||||
|
||||
|
|
@ -25,15 +24,72 @@ qwen
|
|||
> [!note]
|
||||
>
|
||||
> In non-interactive or headless environments (e.g., CI, SSH, containers), you typically **cannot** complete the OAuth browser login flow.
|
||||
> In these cases, please use the API-KEY authentication method.
|
||||
> In these cases, please use the Alibaba Cloud Coding Plan or API Key authentication method.
|
||||
|
||||
## 🚀 Option 2: API-KEY (flexible)
|
||||
## 💳 Option 2: Alibaba Cloud Coding Plan
|
||||
|
||||
Use this if you want more flexibility over which provider and model to use. Supports multiple protocols and providers, including OpenAI, Anthropic, Google GenAI, Alibaba Cloud Bailian, Azure OpenAI, OpenRouter, ModelScope, or a self-hosted compatible endpoint.
|
||||
Use this if you want predictable costs with diverse model options and higher usage quotas.
|
||||
|
||||
- **How it works**: Subscribe to the Coding Plan with a fixed monthly fee, then configure Qwen Code to use the dedicated endpoint and your subscription API key.
|
||||
- **Requirements**: Obtain an active Coding Plan subscription from [Aliyun Bailian](https://bailian.console.aliyun.com/?tab=model#/efm/coding_plan) or [Alibaba Cloud](https://bailian.console.alibabacloud.com/?tab=model#/efm/coding_plan), depending on the region of your account.
|
||||
- **Benefits**: Diverse model options, higher usage quotas, predictable monthly costs, access to a wide range of models (Qwen, GLM, Kimi, Minimax and more).
|
||||
- **Cost & quota**: View [Aliyun Bailian Coding Plan documentation](https://bailian.console.aliyun.com/cn-beijing/?tab=doc#/doc/?type=model&url=3005961).
|
||||
|
||||
Alibaba Cloud Coding Plan is available in two regions:
|
||||
|
||||
| Region | Console URL |
|
||||
| -------------------------------- | ---------------------------------------------------------------------------- |
|
||||
| Aliyun Bailian (aliyun.com) | [bailian.console.aliyun.com](https://bailian.console.aliyun.com) |
|
||||
| Alibaba Cloud (alibabacloud.com) | [bailian.console.alibabacloud.com](https://bailian.console.alibabacloud.com) |
|
||||
|
||||
### Interactive setup
|
||||
|
||||
Enter `qwen` in the terminal to launch Qwen Code, then run the `/auth` command and select **Alibaba Cloud Coding Plan**. Choose your region, then enter your `sk-sp-xxxxxxxxx` key.
|
||||
|
||||
After authentication, use the `/model` command to switch between all Alibaba Cloud Coding Plan supported models (including qwen3.5-plus, qwen3-coder-plus, qwen3-coder-next, qwen3-max, glm-4.7, and kimi-k2.5).
|
||||
|
||||
### Alternative: configure via `settings.json`
|
||||
|
||||
If you prefer to skip the interactive `/auth` flow, add the following to `~/.qwen/settings.json`:
|
||||
|
||||
```json
|
||||
{
|
||||
"modelProviders": {
|
||||
"openai": [
|
||||
{
|
||||
"id": "qwen3-coder-plus",
|
||||
"name": "qwen3-coder-plus (Coding Plan)",
|
||||
"baseUrl": "https://coding.dashscope.aliyuncs.com/v1",
|
||||
"description": "qwen3-coder-plus from Alibaba Cloud Coding Plan",
|
||||
"envKey": "BAILIAN_CODING_PLAN_API_KEY"
|
||||
}
|
||||
]
|
||||
},
|
||||
"env": {
|
||||
"BAILIAN_CODING_PLAN_API_KEY": "sk-sp-xxxxxxxxx"
|
||||
},
|
||||
"security": {
|
||||
"auth": {
|
||||
"selectedType": "openai"
|
||||
}
|
||||
},
|
||||
"model": {
|
||||
"name": "qwen3-coder-plus"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
> [!note]
|
||||
>
|
||||
> The Coding Plan uses a dedicated endpoint (`https://coding.dashscope.aliyuncs.com/v1`) that is different from the standard Dashscope endpoint. Make sure to use the correct `baseUrl`.
|
||||
|
||||
## 🚀 Option 3: API Key (flexible)
|
||||
|
||||
Use this if you want to connect to third-party providers such as OpenAI, Anthropic, Google, Azure OpenAI, OpenRouter, ModelScope, or a self-hosted endpoint. Supports multiple protocols and providers.
|
||||
|
||||
### Recommended: One-file setup via `settings.json`
|
||||
|
||||
The simplest way to get started with API-KEY authentication is to put everything in a single `~/.qwen/settings.json` file. Here's a complete, ready-to-use example:
|
||||
The simplest way to get started with API Key authentication is to put everything in a single `~/.qwen/settings.json` file. Here's a complete, ready-to-use example:
|
||||
|
||||
```json
|
||||
{
|
||||
|
|
@ -66,7 +122,7 @@ What each field does:
|
|||
|
||||
| Field | Description |
|
||||
| ---------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| `modelProviders` | Declares which models are available and how to connect to them. Keys (`openai`, `anthropic`, `gemini`, `vertex-ai`) represent the API protocol. |
|
||||
| `modelProviders` | Declares which models are available and how to connect to them. Keys (`openai`, `anthropic`, `gemini`) represent the API protocol. |
|
||||
| `env` | Stores API keys directly in `settings.json` as a fallback (lowest priority — shell `export` and `.env` files take precedence). |
|
||||
| `security.auth.selectedType` | Tells Qwen Code which protocol to use on startup (e.g. `openai`, `anthropic`, `gemini`). Without this, you'd need to run `/auth` interactively. |
|
||||
| `model.name` | The default model to activate when Qwen Code starts. Must match one of the `id` values in your `modelProviders`. |
|
||||
|
|
@ -77,76 +133,15 @@ After saving the file, just run `qwen` — no interactive `/auth` setup needed.
|
|||
>
|
||||
> The sections below explain each part in more detail. If the quick example above works for you, feel free to skip ahead to [Security notes](#security-notes).
|
||||
|
||||
### Option1: Coding Plan(Aliyun Bailian)
|
||||
|
||||
Use this if you want predictable costs with higher usage quotas for the qwen3-coder-plus model.
|
||||
|
||||
- **How it works**: Subscribe to the Coding Plan with a fixed monthly fee, then configure Qwen Code to use the dedicated endpoint and your subscription API key.
|
||||
- **Requirements**: Obtain an active Coding Plan subscription from [Alibaba Cloud Bailian](https://bailian.console.aliyun.com/cn-beijing/?tab=globalset#/efm/coding_plan).
|
||||
- **Benefits**: Higher usage quotas, predictable monthly costs, access to the latest qwen3-coder-plus model.
|
||||
- **Cost & quota**: View [Alibaba Cloud Bailian Coding Plan documentation](https://bailian.console.aliyun.com/cn-beijing/?tab=doc#/doc/?type=model&url=3005961).
|
||||
|
||||
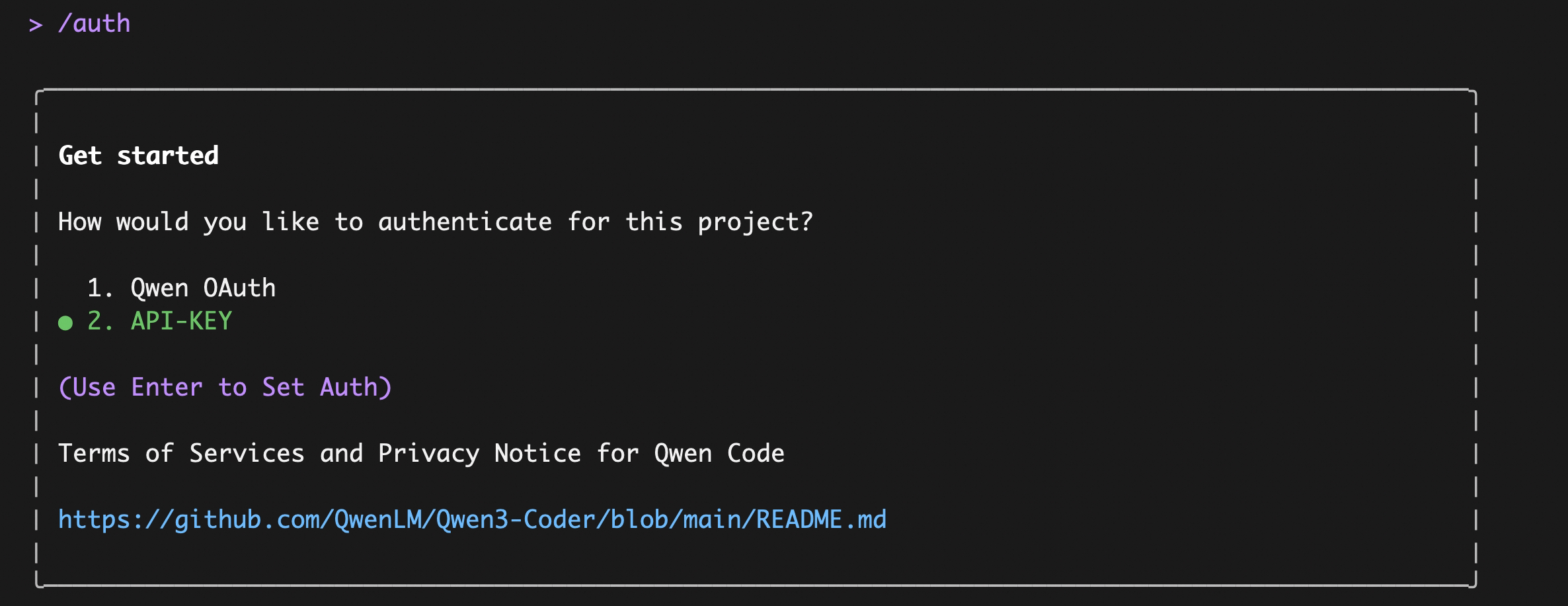
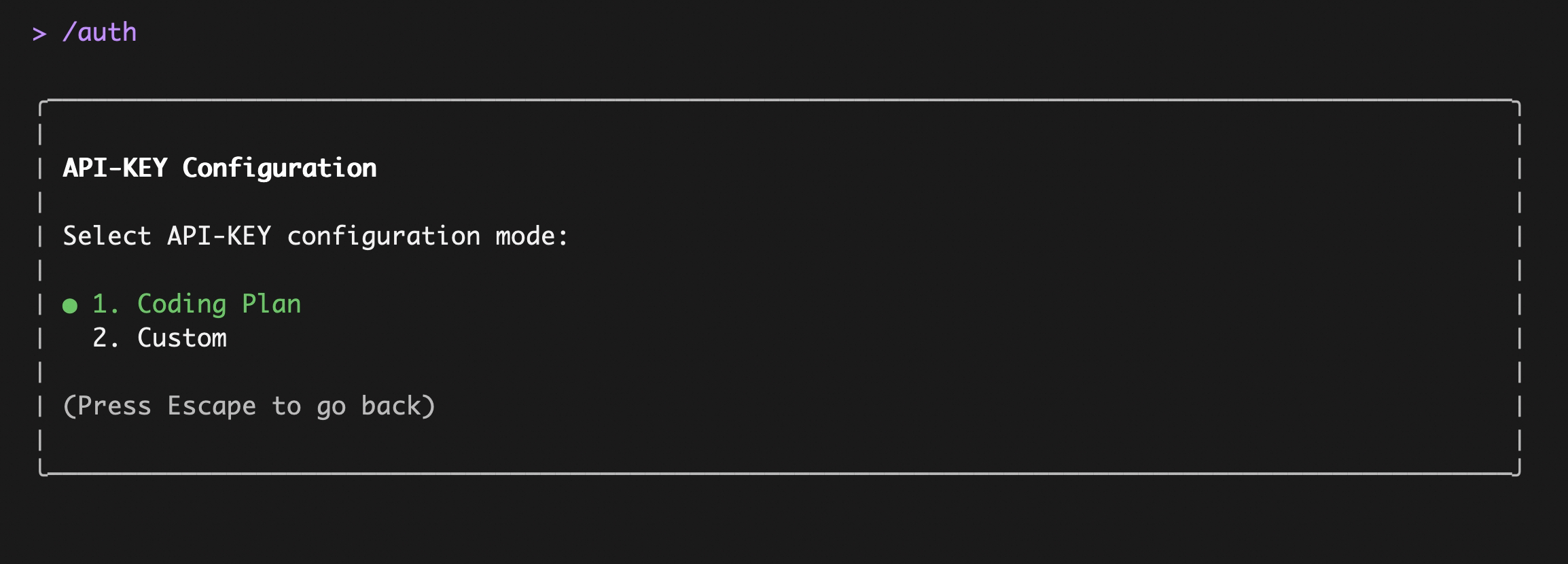
Enter `qwen` in the terminal to launch Qwen Code, then enter the `/auth` command and select `API-KEY`
|
||||
|
||||

|
||||
|
||||
After entering, select `Coding Plan`:
|
||||
|
||||
|
||||
|
||||
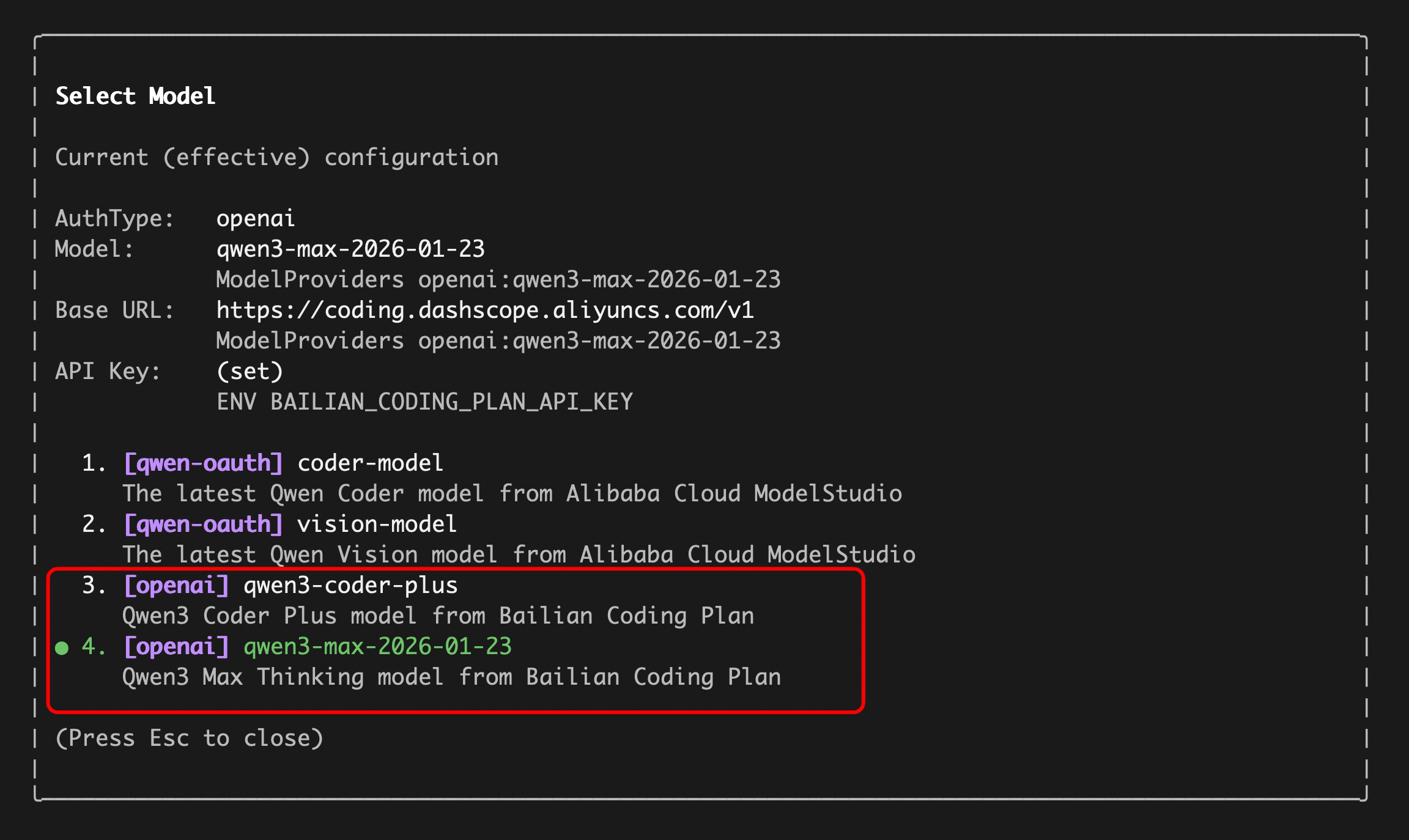
Enter your `sk-sp-xxxxxxxxx` key, then use the `/model` command to switch between all Bailian `Coding Plan` supported models (including qwen3.5-plus, qwen3-coder-plus, qwen3-coder-next, qwen3-max, glm-4.7, and kimi-k2.5):
|
||||
|
||||
|
||||
|
||||
**Alternative: configure Coding Plan via `settings.json`**
|
||||
|
||||
If you prefer to skip the interactive `/auth` flow, add the following to `~/.qwen/settings.json`:
|
||||
|
||||
```json
|
||||
{
|
||||
"modelProviders": {
|
||||
"openai": [
|
||||
{
|
||||
"id": "qwen3-coder-plus",
|
||||
"name": "qwen3-coder-plus (Coding Plan)",
|
||||
"baseUrl": "https://coding.dashscope.aliyuncs.com/v1",
|
||||
"description": "qwen3-coder-plus from Bailian Coding Plan",
|
||||
"envKey": "BAILIAN_CODING_PLAN_API_KEY"
|
||||
}
|
||||
]
|
||||
},
|
||||
"env": {
|
||||
"BAILIAN_CODING_PLAN_API_KEY": "sk-sp-xxxxxxxxx"
|
||||
},
|
||||
"security": {
|
||||
"auth": {
|
||||
"selectedType": "openai"
|
||||
}
|
||||
},
|
||||
"model": {
|
||||
"name": "qwen3-coder-plus"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
> [!note]
|
||||
>
|
||||
> The Coding Plan uses a dedicated endpoint (`https://coding.dashscope.aliyuncs.com/v1`) that is different from the standard Dashscope endpoint. Make sure to use the correct `baseUrl`.
|
||||
|
||||
### Option2: Third-party API-KEY
|
||||
|
||||
Use this if you want to connect to third-party providers such as OpenAI, Anthropic, Google, Azure OpenAI, OpenRouter, ModelScope, or a self-hosted endpoint.
|
||||
|
||||
The key concept is **Model Providers** (`modelProviders`): Qwen Code supports multiple API protocols, not just OpenAI. You configure which providers and models are available by editing `~/.qwen/settings.json`, then switch between them at runtime with the `/model` command.
|
||||
|
||||
#### Supported protocols
|
||||
|
||||
| Protocol | `modelProviders` key | Environment variables | Providers |
|
||||
| ----------------- | -------------------- | ------------------------------------------------------------ | --------------------------------------------------------------------------------------------------- |
|
||||
| OpenAI-compatible | `openai` | `OPENAI_API_KEY`, `OPENAI_BASE_URL`, `OPENAI_MODEL` | OpenAI, Azure OpenAI, OpenRouter, ModelScope, Alibaba Cloud Bailian, any OpenAI-compatible endpoint |
|
||||
| Anthropic | `anthropic` | `ANTHROPIC_API_KEY`, `ANTHROPIC_BASE_URL`, `ANTHROPIC_MODEL` | Anthropic Claude |
|
||||
| Google GenAI | `gemini` | `GEMINI_API_KEY`, `GEMINI_MODEL` | Google Gemini |
|
||||
| Google Vertex AI | `vertex-ai` | `GOOGLE_API_KEY`, `GOOGLE_MODEL` | Google Vertex AI |
|
||||
| Protocol | `modelProviders` key | Environment variables | Providers |
|
||||
| ----------------- | -------------------- | ------------------------------------------------------------ | ------------------------------------------------------------------------------------------- |
|
||||
| OpenAI-compatible | `openai` | `OPENAI_API_KEY`, `OPENAI_BASE_URL`, `OPENAI_MODEL` | OpenAI, Azure OpenAI, OpenRouter, ModelScope, Alibaba Cloud, any OpenAI-compatible endpoint |
|
||||
| Anthropic | `anthropic` | `ANTHROPIC_API_KEY`, `ANTHROPIC_BASE_URL`, `ANTHROPIC_MODEL` | Anthropic Claude |
|
||||
| Google GenAI | `gemini` | `GEMINI_API_KEY`, `GEMINI_MODEL` | Google Gemini |
|
||||
|
||||
#### Step 1: Configure models and providers in `~/.qwen/settings.json`
|
||||
|
||||
|
|
@ -297,6 +292,6 @@ qwen --model "qwen3.5-plus"
|
|||
|
||||
## Security notes
|
||||
|
||||
- Don’t commit API keys to version control.
|
||||
- Don't commit API keys to version control.
|
||||
- Prefer `.qwen/.env` for project-local secrets (and keep it out of git).
|
||||
- Treat your terminal output as sensitive if it prints credentials for verification.
|
||||
|
|
|
|||
|
|
@ -4,11 +4,11 @@ Qwen Code allows you to configure multiple model providers through the `modelPro
|
|||
|
||||
## Overview
|
||||
|
||||
Use `modelProviders` to declare curated model lists per auth type that the `/model` picker can switch between. Keys must be valid auth types (`openai`, `anthropic`, `gemini`, `vertex-ai`, etc.). Each entry requires an `id` and **must include `envKey`**, with optional `name`, `description`, `baseUrl`, and `generationConfig`. Credentials are never persisted in settings; the runtime reads them from `process.env[envKey]`. Qwen OAuth models remain hard-coded and cannot be overridden.
|
||||
Use `modelProviders` to declare curated model lists per auth type that the `/model` picker can switch between. Keys must be valid auth types (`openai`, `anthropic`, `gemini`, etc.). Each entry requires an `id` and **must include `envKey`**, with optional `name`, `description`, `baseUrl`, and `generationConfig`. Credentials are never persisted in settings; the runtime reads them from `process.env[envKey]`. Qwen OAuth models remain hard-coded and cannot be overridden.
|
||||
|
||||
> [!note]
|
||||
>
|
||||
> Only the `/model` command exposes non-default auth types. Anthropic, Gemini, Vertex AI, etc., must be defined via `modelProviders`. The `/auth` command intentionally lists only the built-in Qwen OAuth and OpenAI flows.
|
||||
> Only the `/model` command exposes non-default auth types. Anthropic, Gemini, etc., must be defined via `modelProviders`. The `/auth` command lists Qwen OAuth, Alibaba Cloud Coding Plan, and API Key as the built-in authentication options.
|
||||
|
||||
> [!warning]
|
||||
>
|
||||
|
|
@ -27,7 +27,6 @@ The `modelProviders` object keys must be valid `authType` values. Currently supp
|
|||
| `openai` | OpenAI-compatible APIs (OpenAI, Azure OpenAI, local inference servers like vLLM/Ollama) |
|
||||
| `anthropic` | Anthropic Claude API |
|
||||
| `gemini` | Google Gemini API |
|
||||
| `vertex-ai` | Google Vertex AI |
|
||||
| `qwen-oauth` | Qwen OAuth (hard-coded, cannot be overridden in `modelProviders`) |
|
||||
|
||||
> [!warning]
|
||||
|
|
@ -37,12 +36,12 @@ The `modelProviders` object keys must be valid `authType` values. Currently supp
|
|||
|
||||
Qwen Code uses the following official SDKs to send requests to each provider:
|
||||
|
||||
| Auth Type | SDK Package |
|
||||
| ---------------------- | ----------------------------------------------------------------------------------------------- |
|
||||
| `openai` | [`openai`](https://www.npmjs.com/package/openai) - Official OpenAI Node.js SDK |
|
||||
| `anthropic` | [`@anthropic-ai/sdk`](https://www.npmjs.com/package/@anthropic-ai/sdk) - Official Anthropic SDK |
|
||||
| `gemini` / `vertex-ai` | [`@google/genai`](https://www.npmjs.com/package/@google/genai) - Official Google GenAI SDK |
|
||||
| `qwen-oauth` | [`openai`](https://www.npmjs.com/package/openai) with custom provider (DashScope-compatible) |
|
||||
| Auth Type | SDK Package |
|
||||
| ------------ | ----------------------------------------------------------------------------------------------- |
|
||||
| `openai` | [`openai`](https://www.npmjs.com/package/openai) - Official OpenAI Node.js SDK |
|
||||
| `anthropic` | [`@anthropic-ai/sdk`](https://www.npmjs.com/package/@anthropic-ai/sdk) - Official Anthropic SDK |
|
||||
| `gemini` | [`@google/genai`](https://www.npmjs.com/package/@google/genai) - Official Google GenAI SDK |
|
||||
| `qwen-oauth` | [`openai`](https://www.npmjs.com/package/openai) with custom provider (DashScope-compatible) |
|
||||
|
||||
This means the `baseUrl` you configure should be compatible with the corresponding SDK's expected API format. For example, when using `openai` auth type, the endpoint must accept OpenAI API format requests.
|
||||
|
||||
|
|
@ -64,6 +63,9 @@ This auth type supports not only OpenAI's official API but also any OpenAI-compa
|
|||
"maxRetries": 3,
|
||||
"enableCacheControl": true,
|
||||
"contextWindowSize": 128000,
|
||||
"modalities": {
|
||||
"image": true
|
||||
},
|
||||
"customHeaders": {
|
||||
"X-Client-Request-ID": "req-123"
|
||||
},
|
||||
|
|
@ -183,31 +185,6 @@ This auth type supports not only OpenAI's official API but also any OpenAI-compa
|
|||
}
|
||||
```
|
||||
|
||||
### Google Vertex AI (`vertex-ai`)
|
||||
|
||||
```json
|
||||
{
|
||||
"modelProviders": {
|
||||
"vertex-ai": [
|
||||
{
|
||||
"id": "gemini-1.5-pro-vertex",
|
||||
"name": "Gemini 1.5 Pro (Vertex AI)",
|
||||
"envKey": "GOOGLE_API_KEY",
|
||||
"baseUrl": "https://generativelanguage.googleapis.com",
|
||||
"generationConfig": {
|
||||
"timeout": 90000,
|
||||
"contextWindowSize": 2000000,
|
||||
"samplingParams": {
|
||||
"temperature": 0.2,
|
||||
"max_tokens": 8192
|
||||
}
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Local Self-Hosted Models (via OpenAI-compatible API)
|
||||
|
||||
Most local inference servers (vLLM, Ollama, LM Studio, etc.) provide an OpenAI-compatible API endpoint. Configure them using the `openai` auth type with a local `baseUrl`:
|
||||
|
|
@ -276,15 +253,20 @@ export VLLM_API_KEY="not-needed"
|
|||
|
||||
> [!note]
|
||||
>
|
||||
> <<<<<<< HEAD
|
||||
> The `extra_body` parameter is **only supported for OpenAI-compatible providers** (`openai`, `qwen-oauth`). It is ignored for Anthropic, Gemini, and Vertex AI providers.
|
||||
> =======
|
||||
> The `extra_body` parameter is **only supported for OpenAI-compatible providers** (`openai`, `qwen-oauth`). It is ignored for Anthropic, and Gemini providers.
|
||||
>
|
||||
> > > > > > > main
|
||||
|
||||
## Bailian Coding Plan
|
||||
## Alibaba Cloud Coding Plan
|
||||
|
||||
Bailian Coding Plan provides a pre-configured set of Qwen models optimized for coding tasks. This feature is available for users with Bailian API access and offers a simplified setup experience with automatic model configuration updates.
|
||||
Alibaba Cloud Coding Plan provides a pre-configured set of Qwen models optimized for coding tasks. This feature is available for users with Alibaba Cloud Coding Plan API access and offers a simplified setup experience with automatic model configuration updates.
|
||||
|
||||
### Overview
|
||||
|
||||
When you authenticate with a Bailian Coding Plan API key using the `/auth` command, Qwen Code automatically configures the following models:
|
||||
When you authenticate with an Alibaba Cloud Coding Plan API key using the `/auth` command, Qwen Code automatically configures the following models:
|
||||
|
||||
| Model ID | Name | Description |
|
||||
| ---------------------- | -------------------- | -------------------------------------- |
|
||||
|
|
@ -294,19 +276,19 @@ When you authenticate with a Bailian Coding Plan API key using the `/auth` comma
|
|||
|
||||
### Setup
|
||||
|
||||
1. Obtain a Bailian Coding Plan API key:
|
||||
1. Obtain an Alibaba Cloud Coding Plan API key:
|
||||
- **China**: <https://bailian.console.aliyun.com/?tab=model#/efm/coding_plan>
|
||||
- **International**: <https://modelstudio.console.alibabacloud.com/?tab=dashboard#/efm/coding_plan>
|
||||
2. Run the `/auth` command in Qwen Code
|
||||
3. Select the API-KEY authentication method
|
||||
4. Select your region (China or Global/International)
|
||||
3. Select **Alibaba Cloud Coding Plan**
|
||||
4. Select your region
|
||||
5. Enter your API key when prompted
|
||||
|
||||
The models will be automatically configured and added to your `/model` picker.
|
||||
|
||||
### Regions
|
||||
|
||||
Bailian Coding Plan supports two regions:
|
||||
Alibaba Cloud Coding Plan supports two regions:
|
||||
|
||||
| Region | Endpoint | Description |
|
||||
| -------------------- | ----------------------------------------------- | ----------------------- |
|
||||
|
|
@ -351,7 +333,7 @@ If you prefer to manually configure Coding Plan models, you can add them to your
|
|||
{
|
||||
"id": "qwen3-coder-plus",
|
||||
"name": "qwen3-coder-plus",
|
||||
"description": "Qwen3-Coder via Bailian Coding Plan",
|
||||
"description": "Qwen3-Coder via Alibaba Cloud Coding Plan",
|
||||
"envKey": "YOUR_CUSTOM_ENV_KEY",
|
||||
"baseUrl": "https://coding.dashscope.aliyuncs.com/v1"
|
||||
}
|
||||
|
|
|
|||
|
|
@ -2,7 +2,7 @@
|
|||
|
||||
> [!tip]
|
||||
>
|
||||
> **Authentication / API keys:** Authentication (Qwen OAuth vs OpenAI-compatible API) and auth-related environment variables (like `OPENAI_API_KEY`) are documented in **[Authentication](../configuration/auth)**.
|
||||
> **Authentication / API keys:** Authentication (Qwen OAuth, Alibaba Cloud Coding Plan, or API Key) and auth-related environment variables (like `OPENAI_API_KEY`) are documented in **[Authentication](../configuration/auth)**.
|
||||
|
||||
> [!note]
|
||||
>
|
||||
|
|
@ -125,18 +125,18 @@ Settings are organized into categories. All settings should be placed within the
|
|||
|
||||
#### model
|
||||
|
||||
| Setting | Type | Description | Default |
|
||||
| -------------------------------------------------- | ------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ----------- |
|
||||
| `model.name` | string | The Qwen model to use for conversations. | `undefined` |
|
||||
| `model.maxSessionTurns` | number | Maximum number of user/model/tool turns to keep in a session. -1 means unlimited. | `-1` |
|
||||
| `model.summarizeToolOutput` | object | Enables or disables the summarization of tool output. You can specify the token budget for the summarization using the `tokenBudget` setting. Note: Currently only the `run_shell_command` tool is supported. For example `{"run_shell_command": {"tokenBudget": 2000}}` | `undefined` |
|
||||
| `model.generationConfig` | object | Advanced overrides passed to the underlying content generator. Supports request controls such as `timeout`, `maxRetries`, `enableCacheControl`, `contextWindowSize` (override model's context window size), `customHeaders` (custom HTTP headers for API requests), and `extra_body` (additional body parameters for OpenAI-compatible API requests only), along with fine-tuning knobs under `samplingParams` (for example `temperature`, `top_p`, `max_tokens`). Leave unset to rely on provider defaults. | `undefined` |
|
||||
| `model.chatCompression.contextPercentageThreshold` | number | Sets the threshold for chat history compression as a percentage of the model's total token limit. This is a value between 0 and 1 that applies to both automatic compression and the manual `/compress` command. For example, a value of `0.6` will trigger compression when the chat history exceeds 60% of the token limit. Use `0` to disable compression entirely. | `0.7` |
|
||||
| `model.skipNextSpeakerCheck` | boolean | Skip the next speaker check. | `false` |
|
||||
| `model.skipLoopDetection` | boolean | Disables loop detection checks. Loop detection prevents infinite loops in AI responses but can generate false positives that interrupt legitimate workflows. Enable this option if you experience frequent false positive loop detection interruptions. | `false` |
|
||||
| `model.skipStartupContext` | boolean | Skips sending the startup workspace context (environment summary and acknowledgement) at the beginning of each session. Enable this if you prefer to provide context manually or want to save tokens on startup. | `false` |
|
||||
| `model.enableOpenAILogging` | boolean | Enables logging of OpenAI API calls for debugging and analysis. When enabled, API requests and responses are logged to JSON files. | `false` |
|
||||
| `model.openAILoggingDir` | string | Custom directory path for OpenAI API logs. If not specified, defaults to `logs/openai` in the current working directory. Supports absolute paths, relative paths (resolved from current working directory), and `~` expansion (home directory). | `undefined` |
|
||||
| Setting | Type | Description | Default |
|
||||
| -------------------------------------------------- | ------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ----------- |
|
||||
| `model.name` | string | The Qwen model to use for conversations. | `undefined` |
|
||||
| `model.maxSessionTurns` | number | Maximum number of user/model/tool turns to keep in a session. -1 means unlimited. | `-1` |
|
||||
| `model.summarizeToolOutput` | object | Enables or disables the summarization of tool output. You can specify the token budget for the summarization using the `tokenBudget` setting. Note: Currently only the `run_shell_command` tool is supported. For example `{"run_shell_command": {"tokenBudget": 2000}}` | `undefined` |
|
||||
| `model.generationConfig` | object | Advanced overrides passed to the underlying content generator. Supports request controls such as `timeout`, `maxRetries`, `enableCacheControl`, `contextWindowSize` (override model's context window size), `modalities` (override auto-detected input modalities), `customHeaders` (custom HTTP headers for API requests), and `extra_body` (additional body parameters for OpenAI-compatible API requests only), along with fine-tuning knobs under `samplingParams` (for example `temperature`, `top_p`, `max_tokens`). Leave unset to rely on provider defaults. | `undefined` |
|
||||
| `model.chatCompression.contextPercentageThreshold` | number | Sets the threshold for chat history compression as a percentage of the model's total token limit. This is a value between 0 and 1 that applies to both automatic compression and the manual `/compress` command. For example, a value of `0.6` will trigger compression when the chat history exceeds 60% of the token limit. Use `0` to disable compression entirely. | `0.7` |
|
||||
| `model.skipNextSpeakerCheck` | boolean | Skip the next speaker check. | `false` |
|
||||
| `model.skipLoopDetection` | boolean | Disables loop detection checks. Loop detection prevents infinite loops in AI responses but can generate false positives that interrupt legitimate workflows. Enable this option if you experience frequent false positive loop detection interruptions. | `false` |
|
||||
| `model.skipStartupContext` | boolean | Skips sending the startup workspace context (environment summary and acknowledgement) at the beginning of each session. Enable this if you prefer to provide context manually or want to save tokens on startup. | `false` |
|
||||
| `model.enableOpenAILogging` | boolean | Enables logging of OpenAI API calls for debugging and analysis. When enabled, API requests and responses are logged to JSON files. | `false` |
|
||||
| `model.openAILoggingDir` | string | Custom directory path for OpenAI API logs. If not specified, defaults to `logs/openai` in the current working directory. Supports absolute paths, relative paths (resolved from current working directory), and `~` expansion (home directory). | `undefined` |
|
||||
|
||||
**Example model.generationConfig:**
|
||||
|
||||
|
|
@ -146,6 +146,9 @@ Settings are organized into categories. All settings should be placed within the
|
|||
"generationConfig": {
|
||||
"timeout": 60000,
|
||||
"contextWindowSize": 128000,
|
||||
"modalities": {
|
||||
"image": true
|
||||
},
|
||||
"enableCacheControl": true,
|
||||
"customHeaders": {
|
||||
"X-Client-Request-ID": "req-123"
|
||||
|
|
@ -167,6 +170,10 @@ Settings are organized into categories. All settings should be placed within the
|
|||
|
||||
Overrides the default context window size for the selected model. Qwen Code determines the context window using built-in defaults based on model name matching, with a constant fallback value. Use this setting when a provider's effective context limit differs from Qwen Code's default. This value defines the model's assumed maximum context capacity, not a per-request token limit.
|
||||
|
||||
**modalities:**
|
||||
|
||||
Overrides the auto-detected input modalities for the selected model. Qwen Code automatically detects supported modalities (image, PDF, audio, video) based on model name pattern matching. Use this setting when the auto-detection is incorrect — for example, to enable `pdf` for a model that supports it but isn't recognized. Format: `{ "image": true, "pdf": true, "audio": true, "video": true }`. Omit a key or set it to `false` for unsupported types.
|
||||
|
||||
**customHeaders:**
|
||||
|
||||
Allows you to add custom HTTP headers to all API requests. This is useful for request tracing, monitoring, API gateway routing, or when different models require different headers. If `customHeaders` is defined in `modelProviders[].generationConfig.customHeaders`, it will be used directly; otherwise, headers from `model.generationConfig.customHeaders` will be used. No merging occurs between the two levels.
|
||||
|
|
|
|||
Loading…
Add table
Add a link
Reference in a new issue