mirror of
https://github.com/QwenLM/qwen-code.git
synced 2026-04-28 19:52:02 +00:00
Merge branch 'main' into feat/mcp-tui
This commit is contained in:
commit
1542a2bdc4
114 changed files with 6943 additions and 1324 deletions
|
|
@ -31,6 +31,52 @@ qwen
|
|||
|
||||
Use this if you want more flexibility over which provider and model to use. Supports multiple protocols and providers, including OpenAI, Anthropic, Google GenAI, Alibaba Cloud Bailian, Azure OpenAI, OpenRouter, ModelScope, or a self-hosted compatible endpoint.
|
||||
|
||||
### Recommended: One-file setup via `settings.json`
|
||||
|
||||
The simplest way to get started with API-KEY authentication is to put everything in a single `~/.qwen/settings.json` file. Here's a complete, ready-to-use example:
|
||||
|
||||
```json
|
||||
{
|
||||
"modelProviders": {
|
||||
"openai": [
|
||||
{
|
||||
"id": "qwen3-coder-plus",
|
||||
"name": "qwen3-coder-plus",
|
||||
"baseUrl": "https://dashscope.aliyuncs.com/compatible-mode/v1",
|
||||
"description": "Qwen3-Coder via Dashscope",
|
||||
"envKey": "DASHSCOPE_API_KEY"
|
||||
}
|
||||
]
|
||||
},
|
||||
"env": {
|
||||
"DASHSCOPE_API_KEY": "sk-xxxxxxxxxxxxx"
|
||||
},
|
||||
"security": {
|
||||
"auth": {
|
||||
"selectedType": "openai"
|
||||
}
|
||||
},
|
||||
"model": {
|
||||
"name": "qwen3-coder-plus"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
What each field does:
|
||||
|
||||
| Field | Description |
|
||||
| ---------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| `modelProviders` | Declares which models are available and how to connect to them. Keys (`openai`, `anthropic`, `gemini`, `vertex-ai`) represent the API protocol. |
|
||||
| `env` | Stores API keys directly in `settings.json` as a fallback (lowest priority — shell `export` and `.env` files take precedence). |
|
||||
| `security.auth.selectedType` | Tells Qwen Code which protocol to use on startup (e.g. `openai`, `anthropic`, `gemini`). Without this, you'd need to run `/auth` interactively. |
|
||||
| `model.name` | The default model to activate when Qwen Code starts. Must match one of the `id` values in your `modelProviders`. |
|
||||
|
||||
After saving the file, just run `qwen` — no interactive `/auth` setup needed.
|
||||
|
||||
> [!tip]
|
||||
>
|
||||
> The sections below explain each part in more detail. If the quick example above works for you, feel free to skip ahead to [Security notes](#security-notes).
|
||||
|
||||
### Option1: Coding Plan(Aliyun Bailian)
|
||||
|
||||
Use this if you want predictable costs with higher usage quotas for the qwen3-coder-plus model.
|
||||
|
|
@ -48,10 +94,45 @@ After entering, select `Coding Plan`:
|
|||
|
||||
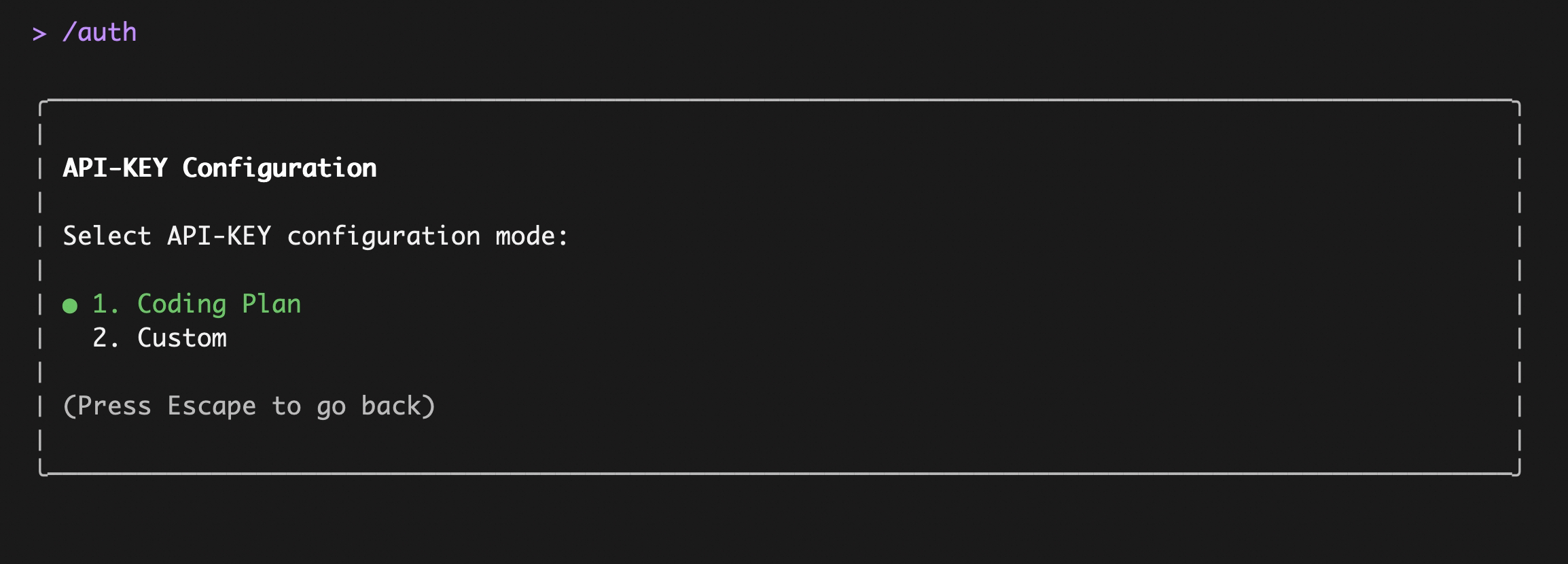
|
||||
|
||||
Enter your `sk-sp-xxxxxxxxx` key, then use the `/model` command to switch between all Bailian `Coding Plan` supported models:
|
||||
Enter your `sk-sp-xxxxxxxxx` key, then use the `/model` command to switch between all Bailian `Coding Plan` supported models (including qwen3.5-plus, qwen3-coder-plus, qwen3-coder-next, qwen3-max, glm-4.7, and kimi-k2.5):
|
||||
|
||||
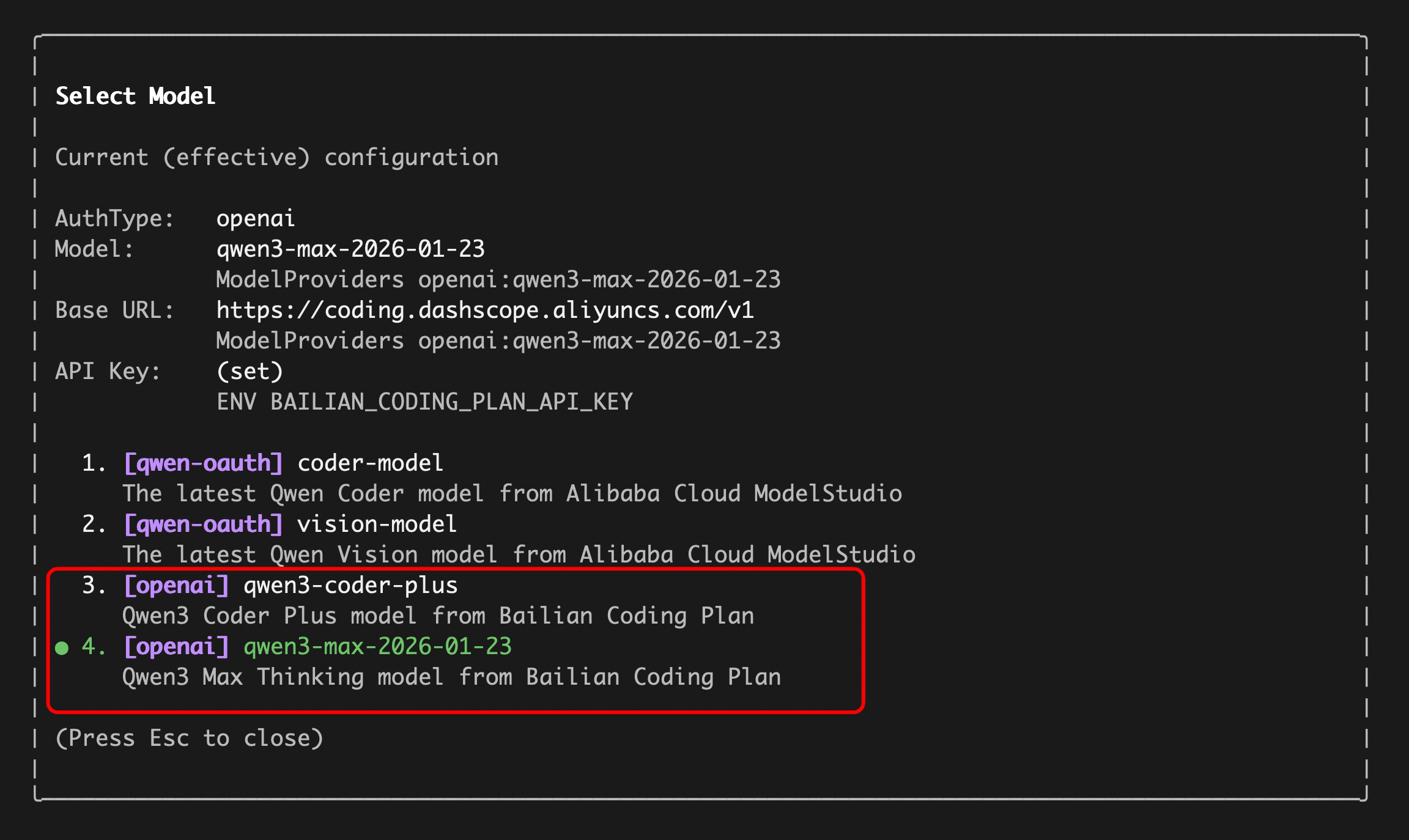
|
||||
|
||||
**Alternative: configure Coding Plan via `settings.json`**
|
||||
|
||||
If you prefer to skip the interactive `/auth` flow, add the following to `~/.qwen/settings.json`:
|
||||
|
||||
```json
|
||||
{
|
||||
"modelProviders": {
|
||||
"openai": [
|
||||
{
|
||||
"id": "qwen3-coder-plus",
|
||||
"name": "qwen3-coder-plus (Coding Plan)",
|
||||
"baseUrl": "https://coding.dashscope.aliyuncs.com/v1",
|
||||
"description": "qwen3-coder-plus from Bailian Coding Plan",
|
||||
"envKey": "BAILIAN_CODING_PLAN_API_KEY"
|
||||
}
|
||||
]
|
||||
},
|
||||
"env": {
|
||||
"BAILIAN_CODING_PLAN_API_KEY": "sk-sp-xxxxxxxxx"
|
||||
},
|
||||
"security": {
|
||||
"auth": {
|
||||
"selectedType": "openai"
|
||||
}
|
||||
},
|
||||
"model": {
|
||||
"name": "qwen3-coder-plus"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
> [!note]
|
||||
>
|
||||
> The Coding Plan uses a dedicated endpoint (`https://coding.dashscope.aliyuncs.com/v1`) that is different from the standard Dashscope endpoint. Make sure to use the correct `baseUrl`.
|
||||
|
||||
### Option2: Third-party API-KEY
|
||||
|
||||
Use this if you want to connect to third-party providers such as OpenAI, Anthropic, Google, Azure OpenAI, OpenRouter, ModelScope, or a self-hosted endpoint.
|
||||
|
|
@ -67,7 +148,7 @@ The key concept is **Model Providers** (`modelProviders`): Qwen Code supports mu
|
|||
| Google GenAI | `gemini` | `GEMINI_API_KEY`, `GEMINI_MODEL` | Google Gemini |
|
||||
| Google Vertex AI | `vertex-ai` | `GOOGLE_API_KEY`, `GOOGLE_MODEL` | Google Vertex AI |
|
||||
|
||||
#### Step 1: Configure `modelProviders` in `~/.qwen/settings.json`
|
||||
#### Step 1: Configure models and providers in `~/.qwen/settings.json`
|
||||
|
||||
Define which models are available for each protocol. Each model entry requires at minimum an `id` and an `envKey` (the environment variable name that holds your API key).
|
||||
|
||||
|
|
@ -75,7 +156,7 @@ Define which models are available for each protocol. Each model entry requires a
|
|||
>
|
||||
> It is recommended to define `modelProviders` in the user-scope `~/.qwen/settings.json` to avoid merge conflicts between project and user settings.
|
||||
|
||||
Edit `~/.qwen/settings.json` (create it if it doesn't exist):
|
||||
Edit `~/.qwen/settings.json` (create it if it doesn't exist). You can mix multiple protocols in a single file — here is a multi-provider example showing just the `modelProviders` section:
|
||||
|
||||
```json
|
||||
{
|
||||
|
|
@ -106,7 +187,11 @@ Edit `~/.qwen/settings.json` (create it if it doesn't exist):
|
|||
}
|
||||
```
|
||||
|
||||
You can mix multiple protocols and models in a single configuration. The `ModelConfig` fields are:
|
||||
> [!tip]
|
||||
>
|
||||
> Don't forget to also set `env`, `security.auth.selectedType`, and `model.name` alongside `modelProviders` — see the [complete example above](#recommended-one-file-setup-via-settingsjson) for reference.
|
||||
|
||||
**`ModelConfig` fields (each entry inside `modelProviders`):**
|
||||
|
||||
| Field | Required | Description |
|
||||
| ------------------ | -------- | -------------------------------------------------------------------- |
|
||||
|
|
@ -118,9 +203,9 @@ You can mix multiple protocols and models in a single configuration. The `ModelC
|
|||
|
||||
> [!note]
|
||||
>
|
||||
> Credentials are **never** stored in `settings.json`. The runtime reads them from the environment variable specified in `envKey`.
|
||||
> When using the `env` field in `settings.json`, credentials are stored in plain text. For better security, prefer `.env` files or shell `export` — see [Step 2](#step-2-set-environment-variables).
|
||||
|
||||
For the full `modelProviders` schema and advanced options like `generationConfig`, `customHeaders`, and `extra_body`, see [Settings Reference → modelProviders](settings.md#modelproviders).
|
||||
For the full `modelProviders` schema and advanced options like `generationConfig`, `customHeaders`, and `extra_body`, see [Model Providers Reference](model-providers.md).
|
||||
|
||||
#### Step 2: Set environment variables
|
||||
|
||||
|
|
@ -165,25 +250,19 @@ If nothing is found, it falls back to your **home directory**:
|
|||
|
||||
**3. `settings.json` → `env` field (lowest priority)**
|
||||
|
||||
You can also define environment variables directly in `~/.qwen/settings.json` under the `env` key. These are loaded as the **lowest-priority fallback** — only applied when a variable is not already set by the system environment or `.env` files.
|
||||
You can also define API keys directly in `~/.qwen/settings.json` under the `env` key. These are loaded as the **lowest-priority fallback** — only applied when a variable is not already set by the system environment or `.env` files.
|
||||
|
||||
```json
|
||||
{
|
||||
"env": {
|
||||
"DASHSCOPE_API_KEY":"sk-...",
|
||||
"DASHSCOPE_API_KEY": "sk-...",
|
||||
"OPENAI_API_KEY": "sk-...",
|
||||
"ANTHROPIC_API_KEY": "sk-ant-...",
|
||||
"GEMINI_API_KEY": "AIza..."
|
||||
},
|
||||
"modelProviders": {
|
||||
...
|
||||
"ANTHROPIC_API_KEY": "sk-ant-..."
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
> [!note]
|
||||
>
|
||||
> This is useful when you want to keep all configuration (providers + credentials) in a single file. However, be mindful that `settings.json` may be shared or synced — prefer `.env` files for sensitive secrets.
|
||||
This is the approach used in the [one-file setup example](#recommended-one-file-setup-via-settingsjson) above. It's convenient for keeping everything in one place, but be mindful that `settings.json` may be shared or synced — prefer `.env` files for sensitive secrets.
|
||||
|
||||
**Priority summary:**
|
||||
|
||||
|
|
|
|||
521
docs/users/configuration/model-providers.md
Normal file
521
docs/users/configuration/model-providers.md
Normal file
|
|
@ -0,0 +1,521 @@
|
|||
# Model Providers
|
||||
|
||||
Qwen Code allows you to configure multiple model providers through the `modelProviders` setting in your `settings.json`. This enables you to switch between different AI models and providers using the `/model` command.
|
||||
|
||||
## Overview
|
||||
|
||||
Use `modelProviders` to declare curated model lists per auth type that the `/model` picker can switch between. Keys must be valid auth types (`openai`, `anthropic`, `gemini`, `vertex-ai`, etc.). Each entry requires an `id` and **must include `envKey`**, with optional `name`, `description`, `baseUrl`, and `generationConfig`. Credentials are never persisted in settings; the runtime reads them from `process.env[envKey]`. Qwen OAuth models remain hard-coded and cannot be overridden.
|
||||
|
||||
> [!note]
|
||||
> Only the `/model` command exposes non-default auth types. Anthropic, Gemini, Vertex AI, etc., must be defined via `modelProviders`. The `/auth` command intentionally lists only the built-in Qwen OAuth and OpenAI flows.
|
||||
|
||||
> [!warning]
|
||||
> **Duplicate model IDs within the same authType:** Defining multiple models with the same `id` under a single `authType` (e.g., two entries with `"id": "gpt-4o"` in `openai`) is currently not supported. If duplicates exist, **the first occurrence wins** and subsequent duplicates are skipped with a warning. Note that the `id` field is used both as the configuration identifier and as the actual model name sent to the API, so using unique IDs (e.g., `gpt-4o-creative`, `gpt-4o-balanced`) is not a viable workaround. This is a known limitation that we plan to address in a future release.
|
||||
|
||||
## Configuration Examples by Auth Type
|
||||
|
||||
Below are comprehensive configuration examples for different authentication types, showing the available parameters and their combinations.
|
||||
|
||||
### Supported Auth Types
|
||||
|
||||
The `modelProviders` object keys must be valid `authType` values. Currently supported auth types are:
|
||||
|
||||
| Auth Type | Description |
|
||||
| ------------ | --------------------------------------------------------------------------------------- |
|
||||
| `openai` | OpenAI-compatible APIs (OpenAI, Azure OpenAI, local inference servers like vLLM/Ollama) |
|
||||
| `anthropic` | Anthropic Claude API |
|
||||
| `gemini` | Google Gemini API |
|
||||
| `vertex-ai` | Google Vertex AI |
|
||||
| `qwen-oauth` | Qwen OAuth (hard-coded, cannot be overridden in `modelProviders`) |
|
||||
|
||||
> [!warning]
|
||||
> If an invalid auth type key is used (e.g., a typo like `"openai-custom"`), the configuration will be **silently skipped** and the models will not appear in the `/model` picker. Always use one of the supported auth type values listed above.
|
||||
|
||||
### SDKs Used for API Requests
|
||||
|
||||
Qwen Code uses the following official SDKs to send requests to each provider:
|
||||
|
||||
| Auth Type | SDK Package |
|
||||
| ---------------------- | ----------------------------------------------------------------------------------------------- |
|
||||
| `openai` | [`openai`](https://www.npmjs.com/package/openai) - Official OpenAI Node.js SDK |
|
||||
| `anthropic` | [`@anthropic-ai/sdk`](https://www.npmjs.com/package/@anthropic-ai/sdk) - Official Anthropic SDK |
|
||||
| `gemini` / `vertex-ai` | [`@google/genai`](https://www.npmjs.com/package/@google/genai) - Official Google GenAI SDK |
|
||||
| `qwen-oauth` | [`openai`](https://www.npmjs.com/package/openai) with custom provider (DashScope-compatible) |
|
||||
|
||||
This means the `baseUrl` you configure should be compatible with the corresponding SDK's expected API format. For example, when using `openai` auth type, the endpoint must accept OpenAI API format requests.
|
||||
|
||||
### OpenAI-compatible providers (`openai`)
|
||||
|
||||
This auth type supports not only OpenAI's official API but also any OpenAI-compatible endpoint, including aggregated model providers like OpenRouter.
|
||||
|
||||
```json
|
||||
{
|
||||
"modelProviders": {
|
||||
"openai": [
|
||||
{
|
||||
"id": "gpt-4o",
|
||||
"name": "GPT-4o",
|
||||
"envKey": "OPENAI_API_KEY",
|
||||
"baseUrl": "https://api.openai.com/v1",
|
||||
"generationConfig": {
|
||||
"timeout": 60000,
|
||||
"maxRetries": 3,
|
||||
"enableCacheControl": true,
|
||||
"contextWindowSize": 128000,
|
||||
"customHeaders": {
|
||||
"X-Client-Request-ID": "req-123"
|
||||
},
|
||||
"extra_body": {
|
||||
"enable_thinking": true,
|
||||
"service_tier": "priority"
|
||||
},
|
||||
"samplingParams": {
|
||||
"temperature": 0.2,
|
||||
"top_p": 0.8,
|
||||
"max_tokens": 4096,
|
||||
"presence_penalty": 0.1,
|
||||
"frequency_penalty": 0.1
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "gpt-4o-mini",
|
||||
"name": "GPT-4o Mini",
|
||||
"envKey": "OPENAI_API_KEY",
|
||||
"baseUrl": "https://api.openai.com/v1",
|
||||
"generationConfig": {
|
||||
"timeout": 30000,
|
||||
"samplingParams": {
|
||||
"temperature": 0.5,
|
||||
"max_tokens": 2048
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "openai/gpt-4o",
|
||||
"name": "GPT-4o (via OpenRouter)",
|
||||
"envKey": "OPENROUTER_API_KEY",
|
||||
"baseUrl": "https://openrouter.ai/api/v1",
|
||||
"generationConfig": {
|
||||
"timeout": 120000,
|
||||
"maxRetries": 3,
|
||||
"samplingParams": {
|
||||
"temperature": 0.7
|
||||
}
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Anthropic (`anthropic`)
|
||||
|
||||
```json
|
||||
{
|
||||
"modelProviders": {
|
||||
"anthropic": [
|
||||
{
|
||||
"id": "claude-3-5-sonnet",
|
||||
"name": "Claude 3.5 Sonnet",
|
||||
"envKey": "ANTHROPIC_API_KEY",
|
||||
"baseUrl": "https://api.anthropic.com/v1",
|
||||
"generationConfig": {
|
||||
"timeout": 120000,
|
||||
"maxRetries": 3,
|
||||
"contextWindowSize": 200000,
|
||||
"samplingParams": {
|
||||
"temperature": 0.7,
|
||||
"max_tokens": 8192,
|
||||
"top_p": 0.9
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "claude-3-opus",
|
||||
"name": "Claude 3 Opus",
|
||||
"envKey": "ANTHROPIC_API_KEY",
|
||||
"baseUrl": "https://api.anthropic.com/v1",
|
||||
"generationConfig": {
|
||||
"timeout": 180000,
|
||||
"samplingParams": {
|
||||
"temperature": 0.3,
|
||||
"max_tokens": 4096
|
||||
}
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Google Gemini (`gemini`)
|
||||
|
||||
```json
|
||||
{
|
||||
"modelProviders": {
|
||||
"gemini": [
|
||||
{
|
||||
"id": "gemini-2.0-flash",
|
||||
"name": "Gemini 2.0 Flash",
|
||||
"envKey": "GEMINI_API_KEY",
|
||||
"baseUrl": "https://generativelanguage.googleapis.com",
|
||||
"capabilities": {
|
||||
"vision": true
|
||||
},
|
||||
"generationConfig": {
|
||||
"timeout": 60000,
|
||||
"maxRetries": 2,
|
||||
"contextWindowSize": 1000000,
|
||||
"schemaCompliance": "auto",
|
||||
"samplingParams": {
|
||||
"temperature": 0.4,
|
||||
"top_p": 0.95,
|
||||
"max_tokens": 8192,
|
||||
"top_k": 40
|
||||
}
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Google Vertex AI (`vertex-ai`)
|
||||
|
||||
```json
|
||||
{
|
||||
"modelProviders": {
|
||||
"vertex-ai": [
|
||||
{
|
||||
"id": "gemini-1.5-pro-vertex",
|
||||
"name": "Gemini 1.5 Pro (Vertex AI)",
|
||||
"envKey": "GOOGLE_API_KEY",
|
||||
"baseUrl": "https://generativelanguage.googleapis.com",
|
||||
"generationConfig": {
|
||||
"timeout": 90000,
|
||||
"contextWindowSize": 2000000,
|
||||
"samplingParams": {
|
||||
"temperature": 0.2,
|
||||
"max_tokens": 8192
|
||||
}
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Local Self-Hosted Models (via OpenAI-compatible API)
|
||||
|
||||
Most local inference servers (vLLM, Ollama, LM Studio, etc.) provide an OpenAI-compatible API endpoint. Configure them using the `openai` auth type with a local `baseUrl`:
|
||||
|
||||
```json
|
||||
{
|
||||
"modelProviders": {
|
||||
"openai": [
|
||||
{
|
||||
"id": "qwen2.5-7b",
|
||||
"name": "Qwen2.5 7B (Ollama)",
|
||||
"envKey": "OLLAMA_API_KEY",
|
||||
"baseUrl": "http://localhost:11434/v1",
|
||||
"generationConfig": {
|
||||
"timeout": 300000,
|
||||
"maxRetries": 1,
|
||||
"contextWindowSize": 32768,
|
||||
"samplingParams": {
|
||||
"temperature": 0.7,
|
||||
"top_p": 0.9,
|
||||
"max_tokens": 4096
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "llama-3.1-8b",
|
||||
"name": "Llama 3.1 8B (vLLM)",
|
||||
"envKey": "VLLM_API_KEY",
|
||||
"baseUrl": "http://localhost:8000/v1",
|
||||
"generationConfig": {
|
||||
"timeout": 120000,
|
||||
"maxRetries": 2,
|
||||
"contextWindowSize": 128000,
|
||||
"samplingParams": {
|
||||
"temperature": 0.6,
|
||||
"max_tokens": 8192
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "local-model",
|
||||
"name": "Local Model (LM Studio)",
|
||||
"envKey": "LMSTUDIO_API_KEY",
|
||||
"baseUrl": "http://localhost:1234/v1",
|
||||
"generationConfig": {
|
||||
"timeout": 60000,
|
||||
"samplingParams": {
|
||||
"temperature": 0.5
|
||||
}
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
For local servers that don't require authentication, you can use any placeholder value for the API key:
|
||||
|
||||
```bash
|
||||
# For Ollama (no auth required)
|
||||
export OLLAMA_API_KEY="ollama"
|
||||
|
||||
# For vLLM (if no auth is configured)
|
||||
export VLLM_API_KEY="not-needed"
|
||||
```
|
||||
|
||||
> [!note]
|
||||
> The `extra_body` parameter is **only supported for OpenAI-compatible providers** (`openai`, `qwen-oauth`). It is ignored for Anthropic, Gemini, and Vertex AI providers.
|
||||
|
||||
## Bailian Coding Plan
|
||||
|
||||
Bailian Coding Plan provides a pre-configured set of Qwen models optimized for coding tasks. This feature is available for users with Bailian API access and offers a simplified setup experience with automatic model configuration updates.
|
||||
|
||||
### Overview
|
||||
|
||||
When you authenticate with a Bailian Coding Plan API key using the `/auth` command, Qwen Code automatically configures the following models:
|
||||
|
||||
| Model ID | Name | Description |
|
||||
| ---------------------- | -------------------- | -------------------------------------- |
|
||||
| `qwen3.5-plus` | qwen3.5-plus | Advanced model with thinking enabled |
|
||||
| `qwen3-coder-plus` | qwen3-coder-plus | Optimized for coding tasks |
|
||||
| `qwen3-max-2026-01-23` | qwen3-max-2026-01-23 | Latest max model with thinking enabled |
|
||||
|
||||
### Setup
|
||||
|
||||
1. Obtain a Bailian Coding Plan API key:
|
||||
- **China**: <https://bailian.console.aliyun.com/?tab=model#/efm/coding_plan>
|
||||
- **International**: <https://modelstudio.console.alibabacloud.com/?tab=dashboard#/efm/coding_plan>
|
||||
2. Run the `/auth` command in Qwen Code
|
||||
3. Select the API-KEY authentication method
|
||||
4. Select your region (China or Global/International)
|
||||
5. Enter your API key when prompted
|
||||
|
||||
The models will be automatically configured and added to your `/model` picker.
|
||||
|
||||
### Regions
|
||||
|
||||
Bailian Coding Plan supports two regions:
|
||||
|
||||
| Region | Endpoint | Description |
|
||||
| -------------------- | ----------------------------------------------- | ----------------------- |
|
||||
| China | `https://coding.dashscope.aliyuncs.com/v1` | Mainland China endpoint |
|
||||
| Global/International | `https://coding-intl.dashscope.aliyuncs.com/v1` | International endpoint |
|
||||
|
||||
The region is selected during authentication and stored in `settings.json` under `codingPlan.region`. To switch regions, re-run the `/auth` command and select a different region.
|
||||
|
||||
### API Key Storage
|
||||
|
||||
When you configure Coding Plan through the `/auth` command, the API key is stored using the reserved environment variable name `BAILIAN_CODING_PLAN_API_KEY`. By default, it is stored in the `settings.env` field of your `settings.json` file.
|
||||
|
||||
> [!warning]
|
||||
> **Security Recommendation**: For better security, it is recommended to move the API key from `settings.json` to a separate `.env` file and load it as an environment variable. For example:
|
||||
>
|
||||
> ```bash
|
||||
> # ~/.qwen/.env
|
||||
> BAILIAN_CODING_PLAN_API_KEY=your-api-key-here
|
||||
> ```
|
||||
>
|
||||
> Then ensure this file is added to your `.gitignore` if you're using project-level settings.
|
||||
|
||||
### Automatic Updates
|
||||
|
||||
Coding Plan model configurations are versioned. When Qwen Code detects a newer version of the model template, you will be prompted to update. Accepting the update will:
|
||||
|
||||
- Replace the existing Coding Plan model configurations with the latest versions
|
||||
- Preserve any custom model configurations you've added manually
|
||||
- Automatically switch to the first model in the updated configuration
|
||||
|
||||
The update process ensures you always have access to the latest model configurations and features without manual intervention.
|
||||
|
||||
### Manual Configuration (Advanced)
|
||||
|
||||
If you prefer to manually configure Coding Plan models, you can add them to your `settings.json` like any OpenAI-compatible provider:
|
||||
|
||||
```json
|
||||
{
|
||||
"modelProviders": {
|
||||
"openai": [
|
||||
{
|
||||
"id": "qwen3-coder-plus",
|
||||
"name": "qwen3-coder-plus",
|
||||
"description": "Qwen3-Coder via Bailian Coding Plan",
|
||||
"envKey": "YOUR_CUSTOM_ENV_KEY",
|
||||
"baseUrl": "https://coding.dashscope.aliyuncs.com/v1"
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
> [!note]
|
||||
> When using manual configuration:
|
||||
|
||||
> - You can use any environment variable name for `envKey`
|
||||
> - You do not need to configure `codingPlan.*`
|
||||
> - **Automatic updates will not apply** to manually configured Coding Plan models
|
||||
|
||||
> [!warning]
|
||||
> If you also use automatic Coding Plan configuration, automatic updates may overwrite your manual configurations if they use the same `envKey` and `baseUrl` as the automatic configuration. To avoid this, ensure your manual configuration uses a different `envKey` if possible.
|
||||
|
||||
## Resolution Layers and Atomicity
|
||||
|
||||
The effective auth/model/credential values are chosen per field using the following precedence (first present wins). You can combine `--auth-type` with `--model` to point directly at a provider entry; these CLI flags run before other layers.
|
||||
|
||||
| Layer (highest → lowest) | authType | model | apiKey | baseUrl | apiKeyEnvKey | proxy |
|
||||
| -------------------------- | ----------------------------------- | ----------------------------------------------- | --------------------------------------------------- | ---------------------------------------------------- | ---------------------- | --------------------------------- |
|
||||
| Programmatic overrides | `/auth` | `/auth` input | `/auth` input | `/auth` input | — | — |
|
||||
| Model provider selection | — | `modelProvider.id` | `env[modelProvider.envKey]` | `modelProvider.baseUrl` | `modelProvider.envKey` | — |
|
||||
| CLI arguments | `--auth-type` | `--model` | `--openaiApiKey` (or provider-specific equivalents) | `--openaiBaseUrl` (or provider-specific equivalents) | — | — |
|
||||
| Environment variables | — | Provider-specific mapping (e.g. `OPENAI_MODEL`) | Provider-specific mapping (e.g. `OPENAI_API_KEY`) | Provider-specific mapping (e.g. `OPENAI_BASE_URL`) | — | — |
|
||||
| Settings (`settings.json`) | `security.auth.selectedType` | `model.name` | `security.auth.apiKey` | `security.auth.baseUrl` | — | — |
|
||||
| Default / computed | Falls back to `AuthType.QWEN_OAUTH` | Built-in default (OpenAI ⇒ `qwen3-coder-plus`) | — | — | — | `Config.getProxy()` if configured |
|
||||
|
||||
\*When present, CLI auth flags override settings. Otherwise, `security.auth.selectedType` or the implicit default determine the auth type. Qwen OAuth and OpenAI are the only auth types surfaced without extra configuration.
|
||||
|
||||
> [!warning]
|
||||
> **Deprecation of `security.auth.apiKey` and `security.auth.baseUrl`:** Directly configuring API credentials via `security.auth.apiKey` and `security.auth.baseUrl` in `settings.json` is deprecated. These settings were used in historical versions for credentials entered through the UI, but the credential input flow was removed in version 0.10.1. These fields will be fully removed in a future release. **It is strongly recommended to migrate to `modelProviders`** for all model and credential configurations. Use `envKey` in `modelProviders` to reference environment variables for secure credential management instead of hardcoding credentials in settings files.
|
||||
|
||||
## Generation Config Layering: The Impermeable Provider Layer
|
||||
|
||||
The configuration resolution follows a strict layering model with one crucial rule: **the modelProvider layer is impermeable**.
|
||||
|
||||
### How it works
|
||||
|
||||
1. **When a modelProvider model IS selected** (e.g., via `/model` command choosing a provider-configured model):
|
||||
- The entire `generationConfig` from the provider is applied **atomically**
|
||||
- **The provider layer is completely impermeable** — lower layers (CLI, env, settings) do not participate in generationConfig resolution at all
|
||||
- All fields defined in `modelProviders[].generationConfig` use the provider's values
|
||||
- All fields **not defined** by the provider are set to `undefined` (not inherited from settings)
|
||||
- This ensures provider configurations act as a complete, self-contained "sealed package"
|
||||
|
||||
2. **When NO modelProvider model is selected** (e.g., using `--model` with a raw model ID, or using CLI/env/settings directly):
|
||||
- The resolution falls through to lower layers
|
||||
- Fields are populated from CLI → env → settings → defaults
|
||||
- This creates a **Runtime Model** (see next section)
|
||||
|
||||
### Per-field precedence for `generationConfig`
|
||||
|
||||
| Priority | Source | Behavior |
|
||||
| -------- | --------------------------------------------- | -------------------------------------------------------------------------------------------------------- |
|
||||
| 1 | Programmatic overrides | Runtime `/model`, `/auth` changes |
|
||||
| 2 | `modelProviders[authType][].generationConfig` | **Impermeable layer** - completely replaces all generationConfig fields; lower layers do not participate |
|
||||
| 3 | `settings.model.generationConfig` | Only used for **Runtime Models** (when no provider model is selected) |
|
||||
| 4 | Content-generator defaults | Provider-specific defaults (e.g., OpenAI vs Gemini) - only for Runtime Models |
|
||||
|
||||
### Atomic field treatment
|
||||
|
||||
The following fields are treated as atomic objects - provider values completely replace the entire object, no merging occurs:
|
||||
|
||||
- `samplingParams` - Temperature, top_p, max_tokens, etc.
|
||||
- `customHeaders` - Custom HTTP headers
|
||||
- `extra_body` - Extra request body parameters
|
||||
|
||||
### Example
|
||||
|
||||
```json
|
||||
// User settings (~/.qwen/settings.json)
|
||||
{
|
||||
"model": {
|
||||
"generationConfig": {
|
||||
"timeout": 30000,
|
||||
"samplingParams": { "temperature": 0.5, "max_tokens": 1000 }
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// modelProviders configuration
|
||||
{
|
||||
"modelProviders": {
|
||||
"openai": [{
|
||||
"id": "gpt-4o",
|
||||
"envKey": "OPENAI_API_KEY",
|
||||
"generationConfig": {
|
||||
"timeout": 60000,
|
||||
"samplingParams": { "temperature": 0.2 }
|
||||
}
|
||||
}]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
When `gpt-4o` is selected from modelProviders:
|
||||
|
||||
- `timeout` = 60000 (from provider, overrides settings)
|
||||
- `samplingParams.temperature` = 0.2 (from provider, completely replaces settings object)
|
||||
- `samplingParams.max_tokens` = **undefined** (not defined in provider, and provider layer does not inherit from settings — fields are explicitly set to undefined if not provided)
|
||||
|
||||
When using a raw model via `--model gpt-4` (not from modelProviders, creates a Runtime Model):
|
||||
|
||||
- `timeout` = 30000 (from settings)
|
||||
- `samplingParams.temperature` = 0.5 (from settings)
|
||||
- `samplingParams.max_tokens` = 1000 (from settings)
|
||||
|
||||
The merge strategy for `modelProviders` itself is REPLACE: the entire `modelProviders` from project settings will override the corresponding section in user settings, rather than merging the two.
|
||||
|
||||
## Provider Models vs Runtime Models
|
||||
|
||||
Qwen Code distinguishes between two types of model configurations:
|
||||
|
||||
### Provider Model
|
||||
|
||||
- Defined in `modelProviders` configuration
|
||||
- Has a complete, atomic configuration package
|
||||
- When selected, its configuration is applied as an impermeable layer
|
||||
- Appears in `/model` command list with full metadata (name, description, capabilities)
|
||||
- Recommended for multi-model workflows and team consistency
|
||||
|
||||
### Runtime Model
|
||||
|
||||
- Created dynamically when using raw model IDs via CLI (`--model`), environment variables, or settings
|
||||
- Not defined in `modelProviders`
|
||||
- Configuration is built by "projecting" through resolution layers (CLI → env → settings → defaults)
|
||||
- Automatically captured as a **RuntimeModelSnapshot** when a complete configuration is detected
|
||||
- Allows reuse without re-entering credentials
|
||||
|
||||
### RuntimeModelSnapshot lifecycle
|
||||
|
||||
When you configure a model without using `modelProviders`, Qwen Code automatically creates a RuntimeModelSnapshot to preserve your configuration:
|
||||
|
||||
```bash
|
||||
# This creates a RuntimeModelSnapshot with ID: $runtime|openai|my-custom-model
|
||||
qwen --auth-type openai --model my-custom-model --openaiApiKey $KEY --openaiBaseUrl https://api.example.com/v1
|
||||
```
|
||||
|
||||
The snapshot:
|
||||
|
||||
- Captures model ID, API key, base URL, and generation config
|
||||
- Persists across sessions (stored in memory during runtime)
|
||||
- Appears in the `/model` command list as a runtime option
|
||||
- Can be switched to using `/model $runtime|openai|my-custom-model`
|
||||
|
||||
### Key differences
|
||||
|
||||
| Aspect | Provider Model | Runtime Model |
|
||||
| ----------------------- | --------------------------------- | ------------------------------------------ |
|
||||
| Configuration source | `modelProviders` in settings | CLI, env, settings layers |
|
||||
| Configuration atomicity | Complete, impermeable package | Layered, each field resolved independently |
|
||||
| Reusability | Always available in `/model` list | Captured as snapshot, appears if complete |
|
||||
| Team sharing | Yes (via committed settings) | No (user-local) |
|
||||
| Credential storage | Reference via `envKey` only | May capture actual key in snapshot |
|
||||
|
||||
### When to use each
|
||||
|
||||
- **Use Provider Models** when: You have standard models shared across a team, need consistent configurations, or want to prevent accidental overrides
|
||||
- **Use Runtime Models** when: Quickly testing a new model, using temporary credentials, or working with ad-hoc endpoints
|
||||
|
||||
## Selection Persistence and Recommendations
|
||||
|
||||
> [!important]
|
||||
> Define `modelProviders` in the user-scope `~/.qwen/settings.json` whenever possible and avoid persisting credential overrides in any scope. Keeping the provider catalog in user settings prevents merge/override conflicts between project and user scopes and ensures `/auth` and `/model` updates always write back to a consistent scope.
|
||||
|
||||
- `/model` and `/auth` persist `model.name` (where applicable) and `security.auth.selectedType` to the closest writable scope that already defines `modelProviders`; otherwise they fall back to the user scope. This keeps workspace/user files in sync with the active provider catalog.
|
||||
- Without `modelProviders`, the resolver mixes CLI/env/settings layers, creating Runtime Models. This is fine for single-provider setups but cumbersome when frequently switching. Define provider catalogs whenever multi-model workflows are common so that switches stay atomic, source-attributed, and debuggable.
|
||||
|
|
@ -148,8 +148,7 @@ Settings are organized into categories. All settings should be placed within the
|
|||
"contextWindowSize": 128000,
|
||||
"enableCacheControl": true,
|
||||
"customHeaders": {
|
||||
"X-Request-ID": "req-123",
|
||||
"X-User-ID": "user-456"
|
||||
"X-Client-Request-ID": "req-123"
|
||||
},
|
||||
"extra_body": {
|
||||
"enable_thinking": true
|
||||
|
|
@ -180,102 +179,6 @@ The `extra_body` field allows you to add custom parameters to the request body s
|
|||
- `"./custom-logs"` - Logs to `./custom-logs` relative to current directory
|
||||
- `"/tmp/openai-logs"` - Logs to absolute path `/tmp/openai-logs`
|
||||
|
||||
#### modelProviders
|
||||
|
||||
Use `modelProviders` to declare curated model lists per auth type that the `/model` picker can switch between. Keys must be valid auth types (`openai`, `anthropic`, `gemini`, `vertex-ai`, etc.). Each entry requires an `id` and **must include `envKey`**, with optional `name`, `description`, `baseUrl`, and `generationConfig`. Credentials are never persisted in settings; the runtime reads them from `process.env[envKey]`. Qwen OAuth models remain hard-coded and cannot be overridden.
|
||||
|
||||
##### Example
|
||||
|
||||
```json
|
||||
{
|
||||
"modelProviders": {
|
||||
"openai": [
|
||||
{
|
||||
"id": "gpt-4o",
|
||||
"name": "GPT-4o",
|
||||
"envKey": "OPENAI_API_KEY",
|
||||
"baseUrl": "https://api.openai.com/v1",
|
||||
"generationConfig": {
|
||||
"timeout": 60000,
|
||||
"maxRetries": 3,
|
||||
"customHeaders": {
|
||||
"X-Model-Version": "v1.0",
|
||||
"X-Request-Priority": "high"
|
||||
},
|
||||
"extra_body": {
|
||||
"enable_thinking": true
|
||||
},
|
||||
"samplingParams": { "temperature": 0.2 }
|
||||
}
|
||||
}
|
||||
],
|
||||
"anthropic": [
|
||||
{
|
||||
"id": "claude-3-5-sonnet",
|
||||
"envKey": "ANTHROPIC_API_KEY",
|
||||
"baseUrl": "https://api.anthropic.com/v1"
|
||||
}
|
||||
],
|
||||
"gemini": [
|
||||
{
|
||||
"id": "gemini-2.0-flash",
|
||||
"name": "Gemini 2.0 Flash",
|
||||
"envKey": "GEMINI_API_KEY",
|
||||
"baseUrl": "https://generativelanguage.googleapis.com"
|
||||
}
|
||||
],
|
||||
"vertex-ai": [
|
||||
{
|
||||
"id": "gemini-1.5-pro-vertex",
|
||||
"envKey": "GOOGLE_API_KEY",
|
||||
"baseUrl": "https://generativelanguage.googleapis.com"
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
> [!note]
|
||||
> Only the `/model` command exposes non-default auth types. Anthropic, Gemini, Vertex AI, etc., must be defined via `modelProviders`. The `/auth` command intentionally lists only the built-in Qwen OAuth and OpenAI flows.
|
||||
|
||||
##### Resolution layers and atomicity
|
||||
|
||||
The effective auth/model/credential values are chosen per field using the following precedence (first present wins). You can combine `--auth-type` with `--model` to point directly at a provider entry; these CLI flags run before other layers.
|
||||
|
||||
| Layer (highest → lowest) | authType | model | apiKey | baseUrl | apiKeyEnvKey | proxy |
|
||||
| -------------------------- | ----------------------------------- | ----------------------------------------------- | --------------------------------------------------- | ---------------------------------------------------- | ---------------------- | --------------------------------- |
|
||||
| Programmatic overrides | `/auth ` | `/auth` input | `/auth` input | `/auth` input | — | — |
|
||||
| Model provider selection | — | `modelProvider.id` | `env[modelProvider.envKey]` | `modelProvider.baseUrl` | `modelProvider.envKey` | — |
|
||||
| CLI arguments | `--auth-type` | `--model` | `--openaiApiKey` (or provider-specific equivalents) | `--openaiBaseUrl` (or provider-specific equivalents) | — | — |
|
||||
| Environment variables | — | Provider-specific mapping (e.g. `OPENAI_MODEL`) | Provider-specific mapping (e.g. `OPENAI_API_KEY`) | Provider-specific mapping (e.g. `OPENAI_BASE_URL`) | — | — |
|
||||
| Settings (`settings.json`) | `security.auth.selectedType` | `model.name` | `security.auth.apiKey` | `security.auth.baseUrl` | — | — |
|
||||
| Default / computed | Falls back to `AuthType.QWEN_OAUTH` | Built-in default (OpenAI ⇒ `qwen3-coder-plus`) | — | — | — | `Config.getProxy()` if configured |
|
||||
|
||||
\*When present, CLI auth flags override settings. Otherwise, `security.auth.selectedType` or the implicit default determine the auth type. Qwen OAuth and OpenAI are the only auth types surfaced without extra configuration.
|
||||
|
||||
Model-provider sourced values are applied atomically: once a provider model is active, every field it defines is protected from lower layers until you manually clear credentials via `/auth`. The final `generationConfig` is the projection across all layers—lower layers only fill gaps left by higher ones, and the provider layer remains impenetrable.
|
||||
|
||||
The merge strategy for `modelProviders` is REPLACE: the entire `modelProviders` from project settings will override the corresponding section in user settings, rather than merging the two.
|
||||
|
||||
##### Generation config layering
|
||||
|
||||
Per-field precedence for `generationConfig`:
|
||||
|
||||
1. Programmatic overrides (e.g. runtime `/model`, `/auth` changes)
|
||||
2. `modelProviders[authType][].generationConfig`
|
||||
3. `settings.model.generationConfig`
|
||||
4. Content-generator defaults (`getDefaultGenerationConfig` for OpenAI, `getParameterValue` for Gemini, etc.)
|
||||
|
||||
`samplingParams`, `customHeaders`, and `extra_body` are all treated atomically; provider values replace the entire object. If `modelProviders[].generationConfig` defines these fields, they are used directly; otherwise, values from `model.generationConfig` are used. No merging occurs between provider and global configuration levels. Defaults from the content generator apply last so each provider retains its tuned baseline.
|
||||
|
||||
##### Selection persistence and recommendations
|
||||
|
||||
> [!important]
|
||||
> Define `modelProviders` in the user-scope `~/.qwen/settings.json` whenever possible and avoid persisting credential overrides in any scope. Keeping the provider catalog in user settings prevents merge/override conflicts between project and user scopes and ensures `/auth` and `/model` updates always write back to a consistent scope.
|
||||
|
||||
- `/model` and `/auth` persist `model.name` (where applicable) and `security.auth.selectedType` to the closest writable scope that already defines `modelProviders`; otherwise they fall back to the user scope. This keeps workspace/user files in sync with the active provider catalog.
|
||||
- Without `modelProviders`, the resolver mixes CLI/env/settings layers, which is fine for single-provider setups but cumbersome when frequently switching. Define provider catalogs whenever multi-model workflows are common so that switches stay atomic, source-attributed, and debuggable.
|
||||
|
||||
#### context
|
||||
|
||||
| Setting | Type | Description | Default |
|
||||
|
|
|
|||
|
|
@ -42,7 +42,7 @@ This document lists the available keyboard shortcuts in Qwen Code.
|
|||
| `Ctrl+R` | Reverse search through input/shell history. |
|
||||
| `Ctrl+Right Arrow` / `Meta+Right Arrow` / `Meta+F` | Move the cursor one word to the right. |
|
||||
| `Ctrl+U` | Delete from the cursor to the beginning of the line. |
|
||||
| `Ctrl+V` | Paste clipboard content. If the clipboard contains an image, it will be saved and a reference to it will be inserted in the prompt. |
|
||||
| `Ctrl+V` (Windows: `Alt+V`) | Paste clipboard content. If the clipboard contains an image, it will be saved and a reference to it will be inserted in the prompt. |
|
||||
| `Ctrl+W` / `Meta+Backspace` / `Ctrl+Backspace` | Delete the word to the left of the cursor. |
|
||||
| `Ctrl+X` / `Meta+Enter` | Open the current input in an external editor. |
|
||||
|
||||
|
|
|
|||
Loading…
Add table
Add a link
Reference in a new issue