mirror of
https://github.com/TheBlewish/Automated-AI-Web-Researcher-Ollama.git
synced 2025-09-01 10:10:01 +00:00
Add files via upload
This commit is contained in:
parent
f117a83248
commit
8acec29d50
10 changed files with 3208 additions and 0 deletions
147
README.md
Normal file
147
README.md
Normal file
|
|
@ -0,0 +1,147 @@
|
|||
# Automated-AI-Web-Researcher-Ollama
|
||||
|
||||
## Description
|
||||
Automated-AI-Web-Researcher is an innovative research assistant that leverages locally-run large language models through Ollama to conduct thorough, automated online research on any given topic or question. Unlike traditional LLM interactions, this tool actually performs structured research by breaking down queries into focused research areas, systematically investigating via web searching and then scraping of relevant websites each area, and compiling it's findings all saved automatically into a text document with all content found and links for the source of each, and whenever you want it to stop it's research you can input a command which then results in the research terminating and the LLM reviewing all the content it found and providing a comprehensive final summary to your original topic or question, and then you can also ask the LLM questions about it's research findings if you would like.
|
||||
|
||||
## Project Demonstration
|
||||
|
||||
[](https://youtu.be/hS7Q1B8N1mQ "My Project Demo")
|
||||
|
||||
Click the image above to watch the demonstration of My Project.
|
||||
|
||||
## Here's how it works:
|
||||
|
||||
1. You provide a research query (e.g., "What year will global population begin to decrease rather than increase according to research?")
|
||||
2. The LLM analyzes your query and generates 5 specific research focus areas, each with assigned priorities based on relevance to the topic or question.
|
||||
3. Starting with the highest priority area, the LLM:
|
||||
- Formulates targeted search queries
|
||||
- Performs web searches
|
||||
- Analyzes search results selecting the most relevant web pages
|
||||
- Scrapes and extracts relevant information for selected web pages
|
||||
- Documents all content it has found during the research session into a research text file including links to websites that the content was retrieved from
|
||||
4. After investigating all focus areas, the LLM based on information is found generates new focus areas, and repeating it's research cycle, often finding new relevant focus areas based on findings in research it has previously found leading to interesting and novel research focuses in some cases.
|
||||
5. You can let it research as long as you would like at any time being able to input a quit command which then stops the research and causes the LLM to review all the content collected so far in full and generate a comprehensive summary to respond to your original query or topic.
|
||||
6. Then the LLM will enter a conversation mode where you can ask specific questions about the research findings if desired.
|
||||
|
||||
The key distinction is that this isn't just a chatbot - it's an automated research assistant that methodically investigates topics and maintains a documented research trail all from a single question or topic of your choosing, and depending on your system and model can do over a hundred searches and content retrievals in a relatively short amount of time, you can leave it running and come back to a full text document with over a hundred pieces of content from relevant websites, and then have it summarise the findings and then even ask it questions about what it found.
|
||||
|
||||
## Features
|
||||
- Automated research planning with prioritized focus areas
|
||||
- Systematic web searching and content analysis
|
||||
- All research content and source URLs saved into a detailed text document
|
||||
- Research summary generation
|
||||
- Post-research Q&A capability about findings
|
||||
- Self-improving search mechanism
|
||||
- Rich console output with status indicators
|
||||
- Comprehensive answer synthesis using web-sourced information
|
||||
- Research conversation mode for exploring findings
|
||||
|
||||
## Installation
|
||||
|
||||
1. Clone the repository:
|
||||
|
||||
```sh
|
||||
git clone https://github.com/TheBlewish/Automated-AI-Web-Researcher-Ollama
|
||||
cd Automated-AI-Web-Researcher-Ollama
|
||||
```
|
||||
|
||||
2. Create and activate a virtual environment:
|
||||
|
||||
```sh
|
||||
python -m venv venv
|
||||
source venv/bin/activate # On Windows, use venv\Scripts\activate
|
||||
```
|
||||
|
||||
3. Install dependencies:
|
||||
|
||||
```sh
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
4. Install and Configure Ollama:
|
||||
- Install Ollama following instructions at https://ollama.ai
|
||||
- Using your selected model file, create a custom model variant with the required context length
|
||||
(phi3:3.8b-mini-128k-instruct or phi3:14b-medium-128k-instruct are recommended)
|
||||
|
||||
Create a file named `modelfile` with these exact contents:
|
||||
|
||||
```
|
||||
FROM your-model-name
|
||||
|
||||
PARAMETER num_ctx 38000
|
||||
```
|
||||
|
||||
Replace "your-model-name" with your chosen model (e.g., phi3:3.8b-mini-128k-instruct).
|
||||
|
||||
Then create the model:
|
||||
|
||||
```sh
|
||||
ollama create research-phi3 -f modelfile
|
||||
```
|
||||
|
||||
Note: This specific configuration is necessary as recent Ollama versions have reduced context windows on models like phi3:3.8b-mini-128k-instruct despite the name suggesting high context which is why the modelfile step is necessary due to the high amount of information being used during the research process.
|
||||
|
||||
## Usage
|
||||
|
||||
1. Start Ollama:
|
||||
|
||||
```sh
|
||||
ollama serve
|
||||
```
|
||||
|
||||
2. Run the researcher:
|
||||
|
||||
```sh
|
||||
python Web-LLM.py
|
||||
```
|
||||
|
||||
3. Start a research session:
|
||||
- Type `@` followed by your research query
|
||||
- Press CTRL+D to submit
|
||||
- Example: `@What year is global population projected to start declining?`
|
||||
|
||||
4. During research you can use the following commands by typing the letter associated with each and submitting with CTRL+D:
|
||||
- Use `s` to show status.
|
||||
- Use `f` to show current focus.
|
||||
- Use `p` to pause and assess research progress, which will give you an assessment from the LLM after reviewing the entire research content whether it can answer your query or not with the content it has so far collected, then it waits for you to input one of two commands, `c` to continue with the research or `q` to terminate it which will result in a summary like if you terminated it without using the pause feature.
|
||||
- Use `q` to quit research.
|
||||
|
||||
5. After research completes:
|
||||
- Wait for the summary to be generated, and review the LLM's findings.
|
||||
- Enter conversation mode to ask specific questions about the findings.
|
||||
- Access the detailed research content found, avaliable in the in a research session text file which will appear in the programs directory, which includes:
|
||||
* All retrieved content
|
||||
* Source URLs for all information
|
||||
* Focus areas investigated
|
||||
* Generated summary
|
||||
|
||||
## Configuration
|
||||
|
||||
The LLM settings can be modified in `llm_config.py`. You must specify your model name in the configuration for the researcher to function. The default configuration is optimized for research tasks with the specified Phi-3 model.
|
||||
|
||||
## Current Status
|
||||
This is a prototype that demonstrates functional automated research capabilities. While still in development, it successfully performs structured research tasks. Currently tested and working well with the phi3:3.8b-mini-128k-instruct model when the context is set as advised previously.
|
||||
|
||||
## Dependencies
|
||||
- Ollama
|
||||
- Python packages listed in requirements.txt
|
||||
- Recommended model: phi3:3.8b-mini-128k-instruct or phi3:14b-medium-128k-instruct (with custom context length as specified)
|
||||
|
||||
## Contributing
|
||||
Contributions are welcome! This is a prototype with room for improvements and new features.
|
||||
|
||||
## License
|
||||
This project is licensed under the MIT License - see the [LICENSE] file for details.
|
||||
|
||||
## Acknowledgments
|
||||
- Ollama team for their local LLM runtime
|
||||
- DuckDuckGo for their search API
|
||||
|
||||
## Personal Note
|
||||
This tool represents an attempt to bridge the gap between simple LLM interactions and genuine research capabilities. By structuring the research process and maintaining documentation, it aims to provide more thorough and verifiable results than traditional LLM conversations. It also represents an attempt to improve on my previous project 'Web-LLM-Assistant-Llamacpp-Ollama' which simply gave LLM's the ability to search and scrape websites to answer questions. This new program, unlike it's predecessor I feel thos program takes that capability and uses it in a novel and actually very useful way, I feel that it is the most advanced and useful way I could conceive of building on my previous program, as a very new programmer this being my second ever program I feel very good about the result, I hope that it hits the mark!
|
||||
Given how much I have now been using it myself, unlike the previous program which felt more like a novelty then an actual tool, this is actually quite useful and unique, but I am quite biased!
|
||||
|
||||
Please enjoy! and feel free to submit any suggestions for improvements, so that we can make this automated AI researcher even more capable.
|
||||
|
||||
## Disclaimer
|
||||
This project is for educational purposes only. Ensure you comply with the terms of service of all APIs and services used.
|
||||
434
Self_Improving_Search.py
Normal file
434
Self_Improving_Search.py
Normal file
|
|
@ -0,0 +1,434 @@
|
|||
import time
|
||||
import re
|
||||
import os
|
||||
from typing import List, Dict, Tuple, Union
|
||||
from colorama import Fore, Style
|
||||
import logging
|
||||
import sys
|
||||
from io import StringIO
|
||||
from web_scraper import get_web_content, can_fetch
|
||||
from llm_config import get_llm_config
|
||||
from llm_response_parser import UltimateLLMResponseParser
|
||||
from llm_wrapper import LLMWrapper
|
||||
from urllib.parse import urlparse
|
||||
|
||||
# Set up logging
|
||||
log_directory = 'logs'
|
||||
if not os.path.exists(log_directory):
|
||||
os.makedirs(log_directory)
|
||||
|
||||
# Configure logger
|
||||
logger = logging.getLogger(__name__)
|
||||
logger.setLevel(logging.INFO)
|
||||
log_file = os.path.join(log_directory, 'llama_output.log')
|
||||
file_handler = logging.FileHandler(log_file)
|
||||
formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
|
||||
file_handler.setFormatter(formatter)
|
||||
logger.handlers = []
|
||||
logger.addHandler(file_handler)
|
||||
logger.propagate = False
|
||||
|
||||
# Suppress other loggers
|
||||
for name in ['root', 'duckduckgo_search', 'requests', 'urllib3']:
|
||||
logging.getLogger(name).setLevel(logging.WARNING)
|
||||
logging.getLogger(name).handlers = []
|
||||
logging.getLogger(name).propagate = False
|
||||
|
||||
class OutputRedirector:
|
||||
def __init__(self, stream=None):
|
||||
self.stream = stream or StringIO()
|
||||
self.original_stdout = sys.stdout
|
||||
self.original_stderr = sys.stderr
|
||||
|
||||
def __enter__(self):
|
||||
sys.stdout = self.stream
|
||||
sys.stderr = self.stream
|
||||
return self.stream
|
||||
|
||||
def __exit__(self, exc_type, exc_val, exc_tb):
|
||||
sys.stdout = self.original_stdout
|
||||
sys.stderr = self.original_stderr
|
||||
|
||||
class EnhancedSelfImprovingSearch:
|
||||
def __init__(self, llm: LLMWrapper, parser: UltimateLLMResponseParser, max_attempts: int = 5):
|
||||
self.llm = llm
|
||||
self.parser = parser
|
||||
self.max_attempts = max_attempts
|
||||
self.llm_config = get_llm_config()
|
||||
|
||||
@staticmethod
|
||||
def initialize_llm():
|
||||
llm_wrapper = LLMWrapper()
|
||||
return llm_wrapper
|
||||
|
||||
def print_thinking(self):
|
||||
print(Fore.MAGENTA + "🧠 Thinking..." + Style.RESET_ALL)
|
||||
|
||||
def print_searching(self):
|
||||
print(Fore.MAGENTA + "📝 Searching..." + Style.RESET_ALL)
|
||||
|
||||
def search_and_improve(self, user_query: str) -> str:
|
||||
attempt = 0
|
||||
while attempt < self.max_attempts:
|
||||
print(f"\n{Fore.CYAN}Search attempt {attempt + 1}:{Style.RESET_ALL}")
|
||||
self.print_searching()
|
||||
|
||||
try:
|
||||
formulated_query, time_range = self.formulate_query(user_query, attempt)
|
||||
|
||||
print(f"{Fore.YELLOW}Original query: {user_query}{Style.RESET_ALL}")
|
||||
print(f"{Fore.YELLOW}Formulated query: {formulated_query}{Style.RESET_ALL}")
|
||||
print(f"{Fore.YELLOW}Time range: {time_range}{Style.RESET_ALL}")
|
||||
|
||||
if not formulated_query:
|
||||
print(f"{Fore.RED}Error: Empty search query. Retrying...{Style.RESET_ALL}")
|
||||
attempt += 1
|
||||
continue
|
||||
|
||||
search_results = self.perform_search(formulated_query, time_range)
|
||||
|
||||
if not search_results:
|
||||
print(f"{Fore.RED}No results found. Retrying with a different query...{Style.RESET_ALL}")
|
||||
attempt += 1
|
||||
continue
|
||||
|
||||
self.display_search_results(search_results)
|
||||
|
||||
selected_urls = self.select_relevant_pages(search_results, user_query)
|
||||
|
||||
if not selected_urls:
|
||||
print(f"{Fore.RED}No relevant URLs found. Retrying...{Style.RESET_ALL}")
|
||||
attempt += 1
|
||||
continue
|
||||
|
||||
print(Fore.MAGENTA + "⚙️ Scraping selected pages..." + Style.RESET_ALL)
|
||||
# Scraping is done without OutputRedirector to ensure messages are visible
|
||||
scraped_content = self.scrape_content(selected_urls)
|
||||
|
||||
if not scraped_content:
|
||||
print(f"{Fore.RED}Failed to scrape content. Retrying...{Style.RESET_ALL}")
|
||||
attempt += 1
|
||||
continue
|
||||
|
||||
self.display_scraped_content(scraped_content)
|
||||
|
||||
self.print_thinking()
|
||||
|
||||
with OutputRedirector() as output:
|
||||
evaluation, decision = self.evaluate_scraped_content(user_query, scraped_content)
|
||||
llm_output = output.getvalue()
|
||||
logger.info(f"LLM Output in evaluate_scraped_content:\n{llm_output}")
|
||||
|
||||
print(f"{Fore.MAGENTA}Evaluation: {evaluation}{Style.RESET_ALL}")
|
||||
print(f"{Fore.MAGENTA}Decision: {decision}{Style.RESET_ALL}")
|
||||
|
||||
if decision == "answer":
|
||||
return self.generate_final_answer(user_query, scraped_content)
|
||||
elif decision == "refine":
|
||||
print(f"{Fore.YELLOW}Refining search...{Style.RESET_ALL}")
|
||||
attempt += 1
|
||||
else:
|
||||
print(f"{Fore.RED}Unexpected decision. Proceeding to answer.{Style.RESET_ALL}")
|
||||
return self.generate_final_answer(user_query, scraped_content)
|
||||
|
||||
except Exception as e:
|
||||
print(f"{Fore.RED}An error occurred during search attempt. Check the log file for details.{Style.RESET_ALL}")
|
||||
logger.error(f"An error occurred during search: {str(e)}", exc_info=True)
|
||||
attempt += 1
|
||||
|
||||
return self.synthesize_final_answer(user_query)
|
||||
|
||||
def evaluate_scraped_content(self, user_query: str, scraped_content: Dict[str, str]) -> Tuple[str, str]:
|
||||
user_query_short = user_query[:200]
|
||||
prompt = f"""
|
||||
Evaluate if the following scraped content contains sufficient information to answer the user's question comprehensively:
|
||||
|
||||
User's question: "{user_query_short}"
|
||||
|
||||
Scraped Content:
|
||||
{self.format_scraped_content(scraped_content)}
|
||||
|
||||
Your task:
|
||||
1. Determine if the scraped content provides enough relevant and detailed information to answer the user's question thoroughly.
|
||||
2. If the information is sufficient, decide to 'answer'. If more information or clarification is needed, decide to 'refine' the search.
|
||||
|
||||
Respond using EXACTLY this format:
|
||||
Evaluation: [Your evaluation of the scraped content]
|
||||
Decision: [ONLY 'answer' if content is sufficient, or 'refine' if more information is needed]
|
||||
"""
|
||||
max_retries = 3
|
||||
for attempt in range(max_retries):
|
||||
try:
|
||||
response_text = self.llm.generate(prompt, max_tokens=200, stop=None)
|
||||
evaluation, decision = self.parse_evaluation_response(response_text)
|
||||
if decision in ['answer', 'refine']:
|
||||
return evaluation, decision
|
||||
except Exception as e:
|
||||
logger.warning(f"Error in evaluate_scraped_content (attempt {attempt + 1}): {str(e)}")
|
||||
|
||||
logger.warning("Failed to get a valid decision in evaluate_scraped_content. Defaulting to 'refine'.")
|
||||
return "Failed to evaluate content.", "refine"
|
||||
|
||||
def parse_evaluation_response(self, response: str) -> Tuple[str, str]:
|
||||
evaluation = ""
|
||||
decision = ""
|
||||
for line in response.strip().split('\n'):
|
||||
if line.startswith('Evaluation:'):
|
||||
evaluation = line.split(':', 1)[1].strip()
|
||||
elif line.startswith('Decision:'):
|
||||
decision = line.split(':', 1)[1].strip().lower()
|
||||
return evaluation, decision
|
||||
|
||||
def formulate_query(self, user_query: str, attempt: int) -> Tuple[str, str]:
|
||||
user_query_short = user_query[:200]
|
||||
prompt = f"""
|
||||
Based on the following user question, formulate a concise and effective search query:
|
||||
"{user_query_short}"
|
||||
Your task:
|
||||
1. Create a search query of 2-5 words that will yield relevant results.
|
||||
2. Determine if a specific time range is needed for the search.
|
||||
Time range options:
|
||||
- 'd': Limit results to the past day. Use for very recent events or rapidly changing information.
|
||||
- 'w': Limit results to the past week. Use for recent events or topics with frequent updates.
|
||||
- 'm': Limit results to the past month. Use for relatively recent information or ongoing events.
|
||||
- 'y': Limit results to the past year. Use for annual events or information that changes yearly.
|
||||
- 'none': No time limit. Use for historical information or topics not tied to a specific time frame.
|
||||
Respond in the following format:
|
||||
Search query: [Your 2-5 word query]
|
||||
Time range: [d/w/m/y/none]
|
||||
Do not provide any additional information or explanation.
|
||||
"""
|
||||
max_retries = 3
|
||||
for retry in range(max_retries):
|
||||
with OutputRedirector() as output:
|
||||
response_text = self.llm.generate(prompt, max_tokens=50, stop=None)
|
||||
llm_output = output.getvalue()
|
||||
logger.info(f"LLM Output in formulate_query:\n{llm_output}")
|
||||
query, time_range = self.parse_query_response(response_text)
|
||||
if query and time_range:
|
||||
return query, time_range
|
||||
return self.fallback_query(user_query), "none"
|
||||
|
||||
def parse_query_response(self, response: str) -> Tuple[str, str]:
|
||||
query = ""
|
||||
time_range = "none"
|
||||
for line in response.strip().split('\n'):
|
||||
if ":" in line:
|
||||
key, value = line.split(":", 1)
|
||||
key = key.strip().lower()
|
||||
value = value.strip()
|
||||
if "query" in key:
|
||||
query = self.clean_query(value)
|
||||
elif "time" in key or "range" in key:
|
||||
time_range = self.validate_time_range(value)
|
||||
return query, time_range
|
||||
|
||||
def clean_query(self, query: str) -> str:
|
||||
query = re.sub(r'["\'\[\]]', '', query)
|
||||
query = re.sub(r'\s+', ' ', query)
|
||||
return query.strip()[:100]
|
||||
|
||||
def validate_time_range(self, time_range: str) -> str:
|
||||
valid_ranges = ['d', 'w', 'm', 'y', 'none']
|
||||
time_range = time_range.lower()
|
||||
return time_range if time_range in valid_ranges else 'none'
|
||||
|
||||
def fallback_query(self, user_query: str) -> str:
|
||||
words = user_query.split()
|
||||
return " ".join(words[:5])
|
||||
|
||||
def perform_search(self, query: str, time_range: str) -> List[Dict]:
|
||||
if not query:
|
||||
return []
|
||||
|
||||
from duckduckgo_search import DDGS
|
||||
|
||||
with DDGS() as ddgs:
|
||||
try:
|
||||
with OutputRedirector() as output:
|
||||
if time_range and time_range != 'none':
|
||||
results = list(ddgs.text(query, timelimit=time_range, max_results=10))
|
||||
else:
|
||||
results = list(ddgs.text(query, max_results=10))
|
||||
ddg_output = output.getvalue()
|
||||
logger.info(f"DDG Output in perform_search:\n{ddg_output}")
|
||||
return [{'number': i+1, **result} for i, result in enumerate(results)]
|
||||
except Exception as e:
|
||||
print(f"{Fore.RED}Search error: {str(e)}{Style.RESET_ALL}")
|
||||
return []
|
||||
|
||||
def display_search_results(self, results: List[Dict]) -> None:
|
||||
"""Display search results with minimal output"""
|
||||
try:
|
||||
if not results:
|
||||
return
|
||||
|
||||
# Only show search success status
|
||||
print(f"\nSearch query sent to DuckDuckGo: {self.last_query}")
|
||||
print(f"Time range sent to DuckDuckGo: {self.last_time_range}")
|
||||
print(f"Number of results: {len(results)}")
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error displaying search results: {str(e)}")
|
||||
|
||||
def select_relevant_pages(self, search_results: List[Dict], user_query: str) -> List[str]:
|
||||
prompt = f"""
|
||||
Given the following search results for the user's question: "{user_query}"
|
||||
Select the 2 most relevant results to scrape and analyze. Explain your reasoning for each selection.
|
||||
|
||||
Search Results:
|
||||
{self.format_results(search_results)}
|
||||
|
||||
Instructions:
|
||||
1. You MUST select exactly 2 result numbers from the search results.
|
||||
2. Choose the results that are most likely to contain comprehensive and relevant information to answer the user's question.
|
||||
3. Provide a brief reason for each selection.
|
||||
|
||||
You MUST respond using EXACTLY this format and nothing else:
|
||||
|
||||
Selected Results: [Two numbers corresponding to the selected results]
|
||||
Reasoning: [Your reasoning for the selections]
|
||||
"""
|
||||
|
||||
max_retries = 3
|
||||
for retry in range(max_retries):
|
||||
with OutputRedirector() as output:
|
||||
response_text = self.llm.generate(prompt, max_tokens=200, stop=None)
|
||||
llm_output = output.getvalue()
|
||||
logger.info(f"LLM Output in select_relevant_pages:\n{llm_output}")
|
||||
|
||||
parsed_response = self.parse_page_selection_response(response_text)
|
||||
if parsed_response and self.validate_page_selection_response(parsed_response, len(search_results)):
|
||||
selected_urls = [result['href'] for result in search_results if result['number'] in parsed_response['selected_results']]
|
||||
|
||||
allowed_urls = [url for url in selected_urls if can_fetch(url)]
|
||||
if allowed_urls:
|
||||
return allowed_urls
|
||||
else:
|
||||
print(f"{Fore.YELLOW}Warning: All selected URLs are disallowed by robots.txt. Retrying selection.{Style.RESET_ALL}")
|
||||
else:
|
||||
print(f"{Fore.YELLOW}Warning: Invalid page selection. Retrying.{Style.RESET_ALL}")
|
||||
|
||||
print(f"{Fore.YELLOW}Warning: All attempts to select relevant pages failed. Falling back to top allowed results.{Style.RESET_ALL}")
|
||||
allowed_urls = [result['href'] for result in search_results if can_fetch(result['href'])][:2]
|
||||
return allowed_urls
|
||||
|
||||
def parse_page_selection_response(self, response: str) -> Dict[str, Union[List[int], str]]:
|
||||
lines = response.strip().split('\n')
|
||||
parsed = {}
|
||||
for line in lines:
|
||||
if line.startswith('Selected Results:'):
|
||||
parsed['selected_results'] = [int(num.strip()) for num in re.findall(r'\d+', line)]
|
||||
elif line.startswith('Reasoning:'):
|
||||
parsed['reasoning'] = line.split(':', 1)[1].strip()
|
||||
return parsed if 'selected_results' in parsed and 'reasoning' in parsed else None
|
||||
|
||||
def validate_page_selection_response(self, parsed_response: Dict[str, Union[List[int], str]], num_results: int) -> bool:
|
||||
if len(parsed_response['selected_results']) != 2:
|
||||
return False
|
||||
if any(num < 1 or num > num_results for num in parsed_response['selected_results']):
|
||||
return False
|
||||
return True
|
||||
|
||||
def format_results(self, results: List[Dict]) -> str:
|
||||
formatted_results = []
|
||||
for result in results:
|
||||
formatted_result = f"{result['number']}. Title: {result.get('title', 'N/A')}\n"
|
||||
formatted_result += f" Snippet: {result.get('body', 'N/A')[:200]}...\n"
|
||||
formatted_result += f" URL: {result.get('href', 'N/A')}\n"
|
||||
formatted_results.append(formatted_result)
|
||||
return "\n".join(formatted_results)
|
||||
|
||||
def scrape_content(self, urls: List[str]) -> Dict[str, str]:
|
||||
scraped_content = {}
|
||||
blocked_urls = []
|
||||
for url in urls:
|
||||
robots_allowed = can_fetch(url)
|
||||
if robots_allowed:
|
||||
content = get_web_content([url])
|
||||
if content:
|
||||
scraped_content.update(content)
|
||||
print(Fore.YELLOW + f"Successfully scraped: {url}" + Style.RESET_ALL)
|
||||
logger.info(f"Successfully scraped: {url}")
|
||||
else:
|
||||
print(Fore.RED + f"Robots.txt disallows scraping of {url}" + Style.RESET_ALL)
|
||||
logger.warning(f"Robots.txt disallows scraping of {url}")
|
||||
else:
|
||||
blocked_urls.append(url)
|
||||
print(Fore.RED + f"Warning: Robots.txt disallows scraping of {url}" + Style.RESET_ALL)
|
||||
logger.warning(f"Robots.txt disallows scraping of {url}")
|
||||
|
||||
print(Fore.CYAN + f"Scraped content received for {len(scraped_content)} URLs" + Style.RESET_ALL)
|
||||
logger.info(f"Scraped content received for {len(scraped_content)} URLs")
|
||||
|
||||
if blocked_urls:
|
||||
print(Fore.RED + f"Warning: {len(blocked_urls)} URL(s) were not scraped due to robots.txt restrictions." + Style.RESET_ALL)
|
||||
logger.warning(f"{len(blocked_urls)} URL(s) were not scraped due to robots.txt restrictions: {', '.join(blocked_urls)}")
|
||||
|
||||
return scraped_content
|
||||
|
||||
def display_scraped_content(self, scraped_content: Dict[str, str]):
|
||||
print(f"\n{Fore.CYAN}Scraped Content:{Style.RESET_ALL}")
|
||||
for url, content in scraped_content.items():
|
||||
print(f"{Fore.GREEN}URL: {url}{Style.RESET_ALL}")
|
||||
print(f"Content: {content[:4000]}...\n")
|
||||
|
||||
def generate_final_answer(self, user_query: str, scraped_content: Dict[str, str]) -> str:
|
||||
user_query_short = user_query[:200]
|
||||
prompt = f"""
|
||||
You are an AI assistant. Provide a comprehensive and detailed answer to the following question using ONLY the information provided in the scraped content. Do not include any references or mention any sources. Answer directly and thoroughly.
|
||||
|
||||
Question: "{user_query_short}"
|
||||
|
||||
Scraped Content:
|
||||
{self.format_scraped_content(scraped_content)}
|
||||
|
||||
Important Instructions:
|
||||
1. Do not use phrases like "Based on the absence of selected results" or similar.
|
||||
2. If the scraped content does not contain enough information to answer the question, say so explicitly and explain what information is missing.
|
||||
3. Provide as much relevant detail as possible from the scraped content.
|
||||
|
||||
Answer:
|
||||
"""
|
||||
max_retries = 3
|
||||
for attempt in range(max_retries):
|
||||
with OutputRedirector() as output:
|
||||
response_text = self.llm.generate(prompt, max_tokens=1024, stop=None)
|
||||
llm_output = output.getvalue()
|
||||
logger.info(f"LLM Output in generate_final_answer:\n{llm_output}")
|
||||
if response_text:
|
||||
logger.info(f"LLM Response:\n{response_text}")
|
||||
return response_text
|
||||
|
||||
error_message = "I apologize, but I couldn't generate a satisfactory answer based on the available information."
|
||||
logger.warning(f"Failed to generate a response after {max_retries} attempts. Returning error message.")
|
||||
return error_message
|
||||
|
||||
def format_scraped_content(self, scraped_content: Dict[str, str]) -> str:
|
||||
formatted_content = []
|
||||
for url, content in scraped_content.items():
|
||||
content = re.sub(r'\s+', ' ', content)
|
||||
formatted_content.append(f"Content from {url}:\n{content}\n")
|
||||
return "\n".join(formatted_content)
|
||||
|
||||
def synthesize_final_answer(self, user_query: str) -> str:
|
||||
prompt = f"""
|
||||
After multiple search attempts, we couldn't find a fully satisfactory answer to the user's question: "{user_query}"
|
||||
|
||||
Please provide the best possible answer you can, acknowledging any limitations or uncertainties.
|
||||
If appropriate, suggest ways the user might refine their question or where they might find more information.
|
||||
|
||||
Respond in a clear, concise, and informative manner.
|
||||
"""
|
||||
try:
|
||||
with OutputRedirector() as output:
|
||||
response_text = self.llm.generate(prompt, max_tokens=self.llm_config.get('max_tokens', 1024), stop=self.llm_config.get('stop', None))
|
||||
llm_output = output.getvalue()
|
||||
logger.info(f"LLM Output in synthesize_final_answer:\n{llm_output}")
|
||||
if response_text:
|
||||
return response_text.strip()
|
||||
except Exception as e:
|
||||
logger.error(f"Error in synthesize_final_answer: {str(e)}", exc_info=True)
|
||||
return "I apologize, but after multiple attempts, I wasn't able to find a satisfactory answer to your question. Please try rephrasing your question or breaking it down into smaller, more specific queries."
|
||||
|
||||
# End of EnhancedSelfImprovingSearch class
|
||||
302
Web-LLM.py
Normal file
302
Web-LLM.py
Normal file
|
|
@ -0,0 +1,302 @@
|
|||
import sys
|
||||
import os
|
||||
from colorama import init, Fore, Style
|
||||
import logging
|
||||
import time
|
||||
from io import StringIO
|
||||
from Self_Improving_Search import EnhancedSelfImprovingSearch
|
||||
from llm_config import get_llm_config
|
||||
from llm_response_parser import UltimateLLMResponseParser
|
||||
from llm_wrapper import LLMWrapper
|
||||
from strategic_analysis_parser import StrategicAnalysisParser
|
||||
from research_manager import ResearchManager
|
||||
|
||||
# Initialize colorama
|
||||
if os.name == 'nt': # Windows-specific initialization
|
||||
init(convert=True, strip=False, wrap=True)
|
||||
else:
|
||||
init()
|
||||
|
||||
# Set up logging
|
||||
log_directory = 'logs'
|
||||
if not os.path.exists(log_directory):
|
||||
os.makedirs(log_directory)
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
logger.setLevel(logging.INFO)
|
||||
log_file = os.path.join(log_directory, 'web_llm.log')
|
||||
file_handler = logging.FileHandler(log_file)
|
||||
formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
|
||||
file_handler.setFormatter(formatter)
|
||||
logger.handlers = []
|
||||
logger.addHandler(file_handler)
|
||||
logger.propagate = False
|
||||
|
||||
# Disable other loggers
|
||||
for name in logging.root.manager.loggerDict:
|
||||
if name != __name__:
|
||||
logging.getLogger(name).disabled = True
|
||||
|
||||
class OutputRedirector:
|
||||
def __init__(self, stream=None):
|
||||
self.stream = stream or StringIO()
|
||||
self.original_stdout = sys.stdout
|
||||
self.original_stderr = sys.stderr
|
||||
|
||||
def __enter__(self):
|
||||
sys.stdout = self.stream
|
||||
sys.stderr = self.stream
|
||||
return self.stream
|
||||
|
||||
def __exit__(self, exc_type, exc_val, exc_tb):
|
||||
sys.stdout = self.original_stdout
|
||||
sys.stderr = self.original_stderr
|
||||
|
||||
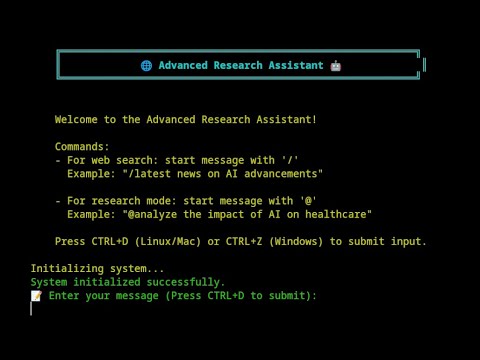
def print_header():
|
||||
print(Fore.CYAN + Style.BRIGHT + """
|
||||
╔══════════════════════════════════════════════════════════╗
|
||||
║ 🌐 Advanced Research Assistant 🤖 ║
|
||||
╚══════════════════════════════════════════════════════════╝
|
||||
""" + Style.RESET_ALL)
|
||||
print(Fore.YELLOW + """
|
||||
Welcome to the Advanced Research Assistant!
|
||||
|
||||
Usage:
|
||||
- Start your research query with '@'
|
||||
Example: "@analyze the impact of AI on healthcare"
|
||||
|
||||
Press CTRL+D (Linux/Mac) or CTRL+Z (Windows) to submit input.
|
||||
""" + Style.RESET_ALL)
|
||||
|
||||
def get_multiline_input() -> str:
|
||||
"""Get multiline input using raw terminal mode for reliable CTRL+D handling"""
|
||||
print(f"{Fore.GREEN}📝 Enter your message (Press CTRL+D to submit):{Style.RESET_ALL}")
|
||||
lines = []
|
||||
|
||||
import termios
|
||||
import tty
|
||||
import sys
|
||||
|
||||
# Save original terminal settings
|
||||
fd = sys.stdin.fileno()
|
||||
old_settings = termios.tcgetattr(fd)
|
||||
|
||||
try:
|
||||
# Set terminal to raw mode
|
||||
tty.setraw(fd)
|
||||
|
||||
current_line = []
|
||||
while True:
|
||||
# Read one character at a time
|
||||
char = sys.stdin.read(1)
|
||||
|
||||
# CTRL+D detection
|
||||
if not char or ord(char) == 4: # EOF or CTRL+D
|
||||
sys.stdout.write('\n') # New line for clean display
|
||||
if current_line:
|
||||
lines.append(''.join(current_line))
|
||||
return ' '.join(lines).strip()
|
||||
|
||||
# Handle special characters
|
||||
elif ord(char) == 13: # Enter
|
||||
sys.stdout.write('\n')
|
||||
lines.append(''.join(current_line))
|
||||
current_line = []
|
||||
|
||||
elif ord(char) == 127: # Backspace
|
||||
if current_line:
|
||||
current_line.pop()
|
||||
sys.stdout.write('\b \b') # Erase character
|
||||
|
||||
elif ord(char) == 3: # CTRL+C
|
||||
sys.stdout.write('\n')
|
||||
return 'q'
|
||||
|
||||
# Normal character
|
||||
elif 32 <= ord(char) <= 126: # Printable characters
|
||||
current_line.append(char)
|
||||
sys.stdout.write(char)
|
||||
|
||||
# Flush output
|
||||
sys.stdout.flush()
|
||||
|
||||
finally:
|
||||
# Restore terminal settings
|
||||
termios.tcsetattr(fd, termios.TCSADRAIN, old_settings)
|
||||
print() # New line for clean display
|
||||
|
||||
def initialize_system():
|
||||
"""Initialize system with proper error checking"""
|
||||
try:
|
||||
print(Fore.YELLOW + "Initializing system..." + Style.RESET_ALL)
|
||||
|
||||
llm_config = get_llm_config()
|
||||
if llm_config['llm_type'] == 'ollama':
|
||||
import requests
|
||||
try:
|
||||
response = requests.get(llm_config['base_url'], timeout=5)
|
||||
if response.status_code != 200:
|
||||
raise ConnectionError("Cannot connect to Ollama server")
|
||||
except requests.exceptions.RequestException:
|
||||
raise ConnectionError(
|
||||
"\nCannot connect to Ollama server!"
|
||||
"\nPlease ensure:"
|
||||
"\n1. Ollama is installed"
|
||||
"\n2. Ollama server is running (try 'ollama serve')"
|
||||
"\n3. The model specified in llm_config.py is pulled"
|
||||
)
|
||||
elif llm_config['llm_type'] == 'llama_cpp':
|
||||
model_path = llm_config.get('model_path')
|
||||
if not model_path or not os.path.exists(model_path):
|
||||
raise FileNotFoundError(
|
||||
f"\nLLama.cpp model not found at: {model_path}"
|
||||
"\nPlease ensure model path in llm_config.py is correct"
|
||||
)
|
||||
|
||||
with OutputRedirector() as output:
|
||||
llm_wrapper = LLMWrapper()
|
||||
try:
|
||||
test_response = llm_wrapper.generate("Test", max_tokens=10)
|
||||
if not test_response:
|
||||
raise ConnectionError("LLM failed to generate response")
|
||||
except Exception as e:
|
||||
raise ConnectionError(f"LLM test failed: {str(e)}")
|
||||
|
||||
parser = UltimateLLMResponseParser()
|
||||
search_engine = EnhancedSelfImprovingSearch(llm_wrapper, parser)
|
||||
research_manager = ResearchManager(llm_wrapper, parser, search_engine)
|
||||
|
||||
print(Fore.GREEN + "System initialized successfully." + Style.RESET_ALL)
|
||||
return llm_wrapper, parser, search_engine, research_manager
|
||||
except Exception as e:
|
||||
logger.error(f"Error initializing system: {str(e)}", exc_info=True)
|
||||
print(Fore.RED + f"System initialization failed: {str(e)}" + Style.RESET_ALL)
|
||||
return None, None, None, None
|
||||
|
||||
def handle_research_mode(research_manager, query):
|
||||
"""Handles research mode operations"""
|
||||
print(f"{Fore.CYAN}Initiating research mode...{Style.RESET_ALL}")
|
||||
|
||||
try:
|
||||
# Start the research
|
||||
research_manager.start_research(query)
|
||||
|
||||
submit_key = "CTRL+Z" if os.name == 'nt' else "CTRL+D"
|
||||
print(f"\n{Fore.YELLOW}Research Running. Available Commands:{Style.RESET_ALL}")
|
||||
print(f"Type command and press {submit_key}:")
|
||||
print("'s' = Show status")
|
||||
print("'f' = Show focus")
|
||||
print("'q' = Quit research")
|
||||
|
||||
while research_manager.is_active():
|
||||
try:
|
||||
command = get_multiline_input().strip().lower()
|
||||
if command == 's':
|
||||
print("\n" + research_manager.get_progress())
|
||||
elif command == 'f':
|
||||
if research_manager.current_focus:
|
||||
print(f"\n{Fore.CYAN}Current Focus:{Style.RESET_ALL}")
|
||||
print(f"Area: {research_manager.current_focus.area}")
|
||||
print(f"Priority: {research_manager.current_focus.priority}")
|
||||
print(f"Reasoning: {research_manager.current_focus.reasoning}")
|
||||
else:
|
||||
print(f"\n{Fore.YELLOW}No current focus area{Style.RESET_ALL}")
|
||||
elif command == 'q':
|
||||
break
|
||||
except KeyboardInterrupt:
|
||||
break
|
||||
|
||||
# Get final summary first
|
||||
summary = research_manager.terminate_research()
|
||||
|
||||
# Ensure research UI is fully cleaned up
|
||||
research_manager._cleanup_research_ui()
|
||||
|
||||
# Now in main terminal, show summary
|
||||
print(f"\n{Fore.GREEN}Research Summary:{Style.RESET_ALL}")
|
||||
print(summary)
|
||||
|
||||
# Only NOW start conversation mode if we have a valid summary
|
||||
if research_manager.research_complete and research_manager.research_summary:
|
||||
time.sleep(0.5) # Small delay to ensure clean transition
|
||||
research_manager.start_conversation_mode()
|
||||
|
||||
return
|
||||
|
||||
except KeyboardInterrupt:
|
||||
print(f"\n{Fore.YELLOW}Research interrupted.{Style.RESET_ALL}")
|
||||
research_manager.terminate_research()
|
||||
except Exception as e:
|
||||
print(f"\n{Fore.RED}Research error: {str(e)}{Style.RESET_ALL}")
|
||||
research_manager.terminate_research()
|
||||
|
||||
def main():
|
||||
print_header()
|
||||
try:
|
||||
llm, parser, search_engine, research_manager = initialize_system()
|
||||
if not all([llm, parser, search_engine, research_manager]):
|
||||
return
|
||||
|
||||
while True:
|
||||
try:
|
||||
# Get input with improved CTRL+D handling
|
||||
user_input = get_multiline_input()
|
||||
|
||||
# Handle immediate CTRL+D (empty input)
|
||||
if user_input == "":
|
||||
user_input = "@quit" # Convert empty CTRL+D to quit command
|
||||
|
||||
user_input = user_input.strip()
|
||||
|
||||
# Check for special quit markers
|
||||
if user_input in ["@quit", "quit", "q"]:
|
||||
print(Fore.YELLOW + "\nGoodbye!" + Style.RESET_ALL)
|
||||
break
|
||||
|
||||
if not user_input:
|
||||
continue
|
||||
|
||||
if user_input.lower() == 'help':
|
||||
print_header()
|
||||
continue
|
||||
|
||||
if user_input.startswith('/'):
|
||||
search_query = user_input[1:].strip()
|
||||
handle_search_mode(search_engine, search_query)
|
||||
|
||||
elif user_input.startswith('@'):
|
||||
research_query = user_input[1:].strip()
|
||||
handle_research_mode(research_manager, research_query)
|
||||
|
||||
else:
|
||||
print(f"{Fore.RED}Please start with '/' for search or '@' for research.{Style.RESET_ALL}")
|
||||
|
||||
except KeyboardInterrupt:
|
||||
print(f"\n{Fore.YELLOW}Exiting program...{Style.RESET_ALL}")
|
||||
break
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Error in main loop: {str(e)}")
|
||||
print(f"{Fore.RED}An error occurred: {str(e)}{Style.RESET_ALL}")
|
||||
continue
|
||||
|
||||
except KeyboardInterrupt:
|
||||
print(f"\n{Fore.YELLOW}Program terminated by user.{Style.RESET_ALL}")
|
||||
|
||||
except Exception as e:
|
||||
logger.critical(f"Critical error: {str(e)}")
|
||||
print(f"{Fore.RED}Critical error: {str(e)}{Style.RESET_ALL}")
|
||||
|
||||
finally:
|
||||
# Ensure proper cleanup on exit
|
||||
try:
|
||||
if 'research_manager' in locals() and research_manager:
|
||||
if hasattr(research_manager, 'ui'):
|
||||
research_manager.ui.cleanup()
|
||||
curses.endwin()
|
||||
except:
|
||||
pass
|
||||
os._exit(0)
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
69
llm_config.py
Normal file
69
llm_config.py
Normal file
|
|
@ -0,0 +1,69 @@
|
|||
# llm_config.py
|
||||
|
||||
LLM_TYPE = "anthropic" # Options: 'llama_cpp', 'ollama', 'openai', 'anthropic'
|
||||
|
||||
# LLM settings for llama_cpp
|
||||
MODEL_PATH = "/home/james/llama.cpp/models/gemma-2-9b-it-Q6_K.gguf" # Replace with your llama.cpp models filepath
|
||||
|
||||
LLM_CONFIG_LLAMA_CPP = {
|
||||
"llm_type": "llama_cpp",
|
||||
"model_path": MODEL_PATH,
|
||||
"n_ctx": 20000, # context size
|
||||
"n_gpu_layers": 0, # number of layers to offload to GPU (-1 for all, 0 for none)
|
||||
"n_threads": 8, # number of threads to use
|
||||
"temperature": 0.7, # temperature for sampling
|
||||
"top_p": 0.9, # top p for sampling
|
||||
"top_k": 40, # top k for sampling
|
||||
"repeat_penalty": 1.1, # repeat penalty
|
||||
"max_tokens": 1024, # max tokens to generate
|
||||
"stop": ["User:", "\n\n"] # stop sequences
|
||||
}
|
||||
|
||||
# LLM settings for Ollama
|
||||
LLM_CONFIG_OLLAMA = {
|
||||
"llm_type": "ollama",
|
||||
"base_url": "http://localhost:11434", # default Ollama server URL
|
||||
"model_name": "custom-phi3-32k-Q4_K_M", # Replace with your Ollama model name
|
||||
"temperature": 0.7,
|
||||
"top_p": 0.9,
|
||||
"n_ctx": 55000,
|
||||
"context_length": 55000,
|
||||
"stop": ["User:", "\n\n"]
|
||||
}
|
||||
|
||||
# LLM settings for OpenAI
|
||||
LLM_CONFIG_OPENAI = {
|
||||
"llm_type": "openai",
|
||||
"api_key": "", # Set via environment variable OPENAI_API_KEY
|
||||
"base_url": None, # Optional: Set to use alternative OpenAI-compatible endpoints
|
||||
"model_name": "gpt-4o", # Required: Specify the model to use
|
||||
"temperature": 0.7,
|
||||
"top_p": 0.9,
|
||||
"max_tokens": 4096,
|
||||
"stop": ["User:", "\n\n"],
|
||||
"presence_penalty": 0,
|
||||
"frequency_penalty": 0
|
||||
}
|
||||
|
||||
# LLM settings for Anthropic
|
||||
LLM_CONFIG_ANTHROPIC = {
|
||||
"llm_type": "anthropic",
|
||||
"api_key": "", # Set via environment variable ANTHROPIC_API_KEY
|
||||
"model_name": "claude-3-5-sonnet-latest", # Required: Specify the model to use
|
||||
"temperature": 0.7,
|
||||
"top_p": 0.9,
|
||||
"max_tokens": 4096,
|
||||
"stop": ["User:", "\n\n"]
|
||||
}
|
||||
|
||||
def get_llm_config():
|
||||
if LLM_TYPE == "llama_cpp":
|
||||
return LLM_CONFIG_LLAMA_CPP
|
||||
elif LLM_TYPE == "ollama":
|
||||
return LLM_CONFIG_OLLAMA
|
||||
elif LLM_TYPE == "openai":
|
||||
return LLM_CONFIG_OPENAI
|
||||
elif LLM_TYPE == "anthropic":
|
||||
return LLM_CONFIG_ANTHROPIC
|
||||
else:
|
||||
raise ValueError(f"Invalid LLM_TYPE: {LLM_TYPE}")
|
||||
240
llm_response_parser.py
Normal file
240
llm_response_parser.py
Normal file
|
|
@ -0,0 +1,240 @@
|
|||
import re
|
||||
from typing import Dict, List, Union, Optional
|
||||
import logging
|
||||
import json
|
||||
from strategic_analysis_parser import StrategicAnalysisParser, AnalysisResult, ResearchFocus
|
||||
|
||||
# Set up logging
|
||||
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class UltimateLLMResponseParser:
|
||||
def __init__(self):
|
||||
self.decision_keywords = {
|
||||
'refine': ['refine', 'need more info', 'insufficient', 'unclear', 'more research', 'additional search'],
|
||||
'answer': ['answer', 'sufficient', 'enough info', 'can respond', 'adequate', 'comprehensive']
|
||||
}
|
||||
self.section_identifiers = [
|
||||
('decision', r'(?i)decision\s*:'),
|
||||
('reasoning', r'(?i)reasoning\s*:'),
|
||||
('selected_results', r'(?i)selected results\s*:'),
|
||||
('response', r'(?i)response\s*:')
|
||||
]
|
||||
# Initialize strategic analysis parser
|
||||
self.strategic_parser = StrategicAnalysisParser()
|
||||
|
||||
def parse_llm_response(self, response: str, mode: str = 'search') -> Dict[str, Union[str, List[int], AnalysisResult]]:
|
||||
"""
|
||||
Parse LLM response based on mode
|
||||
|
||||
Args:
|
||||
response (str): The LLM's response text
|
||||
mode (str): 'search' for web search, 'research' for strategic analysis
|
||||
|
||||
Returns:
|
||||
Dict containing parsed response
|
||||
"""
|
||||
logger.info(f"Starting to parse LLM response in {mode} mode")
|
||||
|
||||
if mode == 'research':
|
||||
return self._parse_research_response(response)
|
||||
|
||||
# Original search mode parsing
|
||||
result = {
|
||||
'decision': None,
|
||||
'reasoning': None,
|
||||
'selected_results': [],
|
||||
'response': None
|
||||
}
|
||||
|
||||
parsing_strategies = [
|
||||
self._parse_structured_response,
|
||||
self._parse_json_response,
|
||||
self._parse_unstructured_response,
|
||||
self._parse_implicit_response
|
||||
]
|
||||
|
||||
for strategy in parsing_strategies:
|
||||
try:
|
||||
parsed_result = strategy(response)
|
||||
if self._is_valid_result(parsed_result):
|
||||
result.update(parsed_result)
|
||||
logger.info(f"Successfully parsed using strategy: {strategy.__name__}")
|
||||
break
|
||||
except Exception as e:
|
||||
logger.warning(f"Error in parsing strategy {strategy.__name__}: {str(e)}")
|
||||
|
||||
if not self._is_valid_result(result):
|
||||
logger.warning("All parsing strategies failed. Using fallback parsing.")
|
||||
result = self._fallback_parsing(response)
|
||||
|
||||
result = self._post_process_result(result)
|
||||
|
||||
logger.info("Finished parsing LLM response")
|
||||
return result
|
||||
|
||||
def _parse_research_response(self, response: str) -> Dict[str, Union[str, AnalysisResult]]:
|
||||
"""Handle research mode specific parsing"""
|
||||
try:
|
||||
analysis_result = self.strategic_parser.parse_analysis(response)
|
||||
if analysis_result:
|
||||
return {
|
||||
'mode': 'research',
|
||||
'analysis_result': analysis_result,
|
||||
'error': None
|
||||
}
|
||||
else:
|
||||
logger.error("Failed to parse strategic analysis")
|
||||
return {
|
||||
'mode': 'research',
|
||||
'analysis_result': None,
|
||||
'error': 'Failed to parse strategic analysis'
|
||||
}
|
||||
except Exception as e:
|
||||
logger.error(f"Error in research response parsing: {str(e)}")
|
||||
return {
|
||||
'mode': 'research',
|
||||
'analysis_result': None,
|
||||
'error': str(e)
|
||||
}
|
||||
|
||||
def parse_search_query(self, query_response: str) -> Dict[str, str]:
|
||||
"""Parse search query formulation response"""
|
||||
try:
|
||||
lines = query_response.strip().split('\n')
|
||||
result = {
|
||||
'query': '',
|
||||
'time_range': 'none'
|
||||
}
|
||||
|
||||
for line in lines:
|
||||
if ':' in line:
|
||||
key, value = line.split(':', 1)
|
||||
key = key.strip().lower()
|
||||
value = value.strip()
|
||||
|
||||
if 'query' in key:
|
||||
result['query'] = self._clean_query(value)
|
||||
elif 'time' in key or 'range' in key:
|
||||
result['time_range'] = self._validate_time_range(value)
|
||||
|
||||
return result
|
||||
except Exception as e:
|
||||
logger.error(f"Error parsing search query: {str(e)}")
|
||||
return {'query': '', 'time_range': 'none'}
|
||||
|
||||
def _parse_structured_response(self, response: str) -> Dict[str, Union[str, List[int]]]:
|
||||
result = {}
|
||||
for key, pattern in self.section_identifiers:
|
||||
match = re.search(f'{pattern}(.*?)(?={"|".join([p for k, p in self.section_identifiers if k != key])}|$)',
|
||||
response, re.IGNORECASE | re.DOTALL)
|
||||
if match:
|
||||
result[key] = match.group(1).strip()
|
||||
|
||||
if 'selected_results' in result:
|
||||
result['selected_results'] = self._extract_numbers(result['selected_results'])
|
||||
|
||||
return result
|
||||
|
||||
def _parse_json_response(self, response: str) -> Dict[str, Union[str, List[int]]]:
|
||||
try:
|
||||
json_match = re.search(r'\{.*\}', response, re.DOTALL)
|
||||
if json_match:
|
||||
json_str = json_match.group(0)
|
||||
parsed_json = json.loads(json_str)
|
||||
return {k: v for k, v in parsed_json.items()
|
||||
if k in ['decision', 'reasoning', 'selected_results', 'response']}
|
||||
except json.JSONDecodeError:
|
||||
pass
|
||||
return {}
|
||||
|
||||
def _parse_unstructured_response(self, response: str) -> Dict[str, Union[str, List[int]]]:
|
||||
result = {}
|
||||
lines = response.split('\n')
|
||||
current_section = None
|
||||
|
||||
for line in lines:
|
||||
section_match = re.match(r'(.+?)[:.-](.+)', line)
|
||||
if section_match:
|
||||
key = self._match_section_to_key(section_match.group(1))
|
||||
if key:
|
||||
current_section = key
|
||||
result[key] = section_match.group(2).strip()
|
||||
elif current_section:
|
||||
result[current_section] += ' ' + line.strip()
|
||||
|
||||
if 'selected_results' in result:
|
||||
result['selected_results'] = self._extract_numbers(result['selected_results'])
|
||||
|
||||
return result
|
||||
|
||||
def _parse_implicit_response(self, response: str) -> Dict[str, Union[str, List[int]]]:
|
||||
result = {}
|
||||
|
||||
decision = self._infer_decision(response)
|
||||
if decision:
|
||||
result['decision'] = decision
|
||||
|
||||
numbers = self._extract_numbers(response)
|
||||
if numbers:
|
||||
result['selected_results'] = numbers
|
||||
|
||||
if not result:
|
||||
result['response'] = response.strip()
|
||||
|
||||
return result
|
||||
|
||||
def _fallback_parsing(self, response: str) -> Dict[str, Union[str, List[int]]]:
|
||||
return {
|
||||
'decision': self._infer_decision(response),
|
||||
'reasoning': None,
|
||||
'selected_results': self._extract_numbers(response),
|
||||
'response': response.strip()
|
||||
}
|
||||
|
||||
def _post_process_result(self, result: Dict[str, Union[str, List[int]]]) -> Dict[str, Union[str, List[int]]]:
|
||||
if result['decision'] not in ['refine', 'answer']:
|
||||
result['decision'] = self._infer_decision(str(result))
|
||||
|
||||
if not isinstance(result['selected_results'], list):
|
||||
result['selected_results'] = self._extract_numbers(str(result['selected_results']))
|
||||
|
||||
result['selected_results'] = result['selected_results'][:2]
|
||||
|
||||
if not result['reasoning']:
|
||||
result['reasoning'] = f"Based on the {'presence' if result['selected_results'] else 'absence'} of selected results and the overall content."
|
||||
|
||||
if not result['response']:
|
||||
result['response'] = result.get('reasoning', 'No clear response found.')
|
||||
|
||||
return result
|
||||
|
||||
def _match_section_to_key(self, section: str) -> Optional[str]:
|
||||
for key, pattern in self.section_identifiers:
|
||||
if re.search(pattern, section, re.IGNORECASE):
|
||||
return key
|
||||
return None
|
||||
|
||||
def _extract_numbers(self, text: str) -> List[int]:
|
||||
return [int(num) for num in re.findall(r'\b(?:10|[1-9])\b', text)]
|
||||
|
||||
def _infer_decision(self, text: str) -> str:
|
||||
text = text.lower()
|
||||
refine_score = sum(text.count(keyword) for keyword in self.decision_keywords['refine'])
|
||||
answer_score = sum(text.count(keyword) for keyword in self.decision_keywords['answer'])
|
||||
return 'refine' if refine_score > answer_score else 'answer'
|
||||
|
||||
def _is_valid_result(self, result: Dict[str, Union[str, List[int]]]) -> bool:
|
||||
return bool(result.get('decision') or result.get('response') or result.get('selected_results'))
|
||||
|
||||
def _clean_query(self, query: str) -> str:
|
||||
"""Clean and validate search query"""
|
||||
query = re.sub(r'["\'\[\]]', '', query)
|
||||
query = re.sub(r'\s+', ' ', query)
|
||||
return query.strip()[:100]
|
||||
|
||||
def _validate_time_range(self, time_range: str) -> str:
|
||||
"""Validate time range value"""
|
||||
valid_ranges = ['d', 'w', 'm', 'y', 'none']
|
||||
time_range = time_range.lower()
|
||||
return time_range if time_range in valid_ranges else 'none'
|
||||
154
llm_wrapper.py
Normal file
154
llm_wrapper.py
Normal file
|
|
@ -0,0 +1,154 @@
|
|||
import os
|
||||
from llama_cpp import Llama
|
||||
import requests
|
||||
import json
|
||||
from llm_config import get_llm_config
|
||||
from openai import OpenAI
|
||||
from anthropic import Anthropic
|
||||
|
||||
class LLMWrapper:
|
||||
def __init__(self):
|
||||
self.llm_config = get_llm_config()
|
||||
self.llm_type = self.llm_config.get('llm_type', 'llama_cpp')
|
||||
|
||||
if self.llm_type == 'llama_cpp':
|
||||
self.llm = self._initialize_llama_cpp()
|
||||
elif self.llm_type == 'ollama':
|
||||
self.base_url = self.llm_config.get('base_url', 'http://localhost:11434')
|
||||
self.model_name = self.llm_config.get('model_name', 'your_model_name')
|
||||
elif self.llm_type == 'openai':
|
||||
self._initialize_openai()
|
||||
elif self.llm_type == 'anthropic':
|
||||
self._initialize_anthropic()
|
||||
else:
|
||||
raise ValueError(f"Unsupported LLM type: {self.llm_type}")
|
||||
|
||||
def _initialize_llama_cpp(self):
|
||||
return Llama(
|
||||
model_path=self.llm_config.get('model_path'),
|
||||
n_ctx=self.llm_config.get('n_ctx', 55000),
|
||||
n_gpu_layers=self.llm_config.get('n_gpu_layers', 0),
|
||||
n_threads=self.llm_config.get('n_threads', 8),
|
||||
verbose=False
|
||||
)
|
||||
|
||||
def _initialize_openai(self):
|
||||
api_key = os.getenv('OPENAI_API_KEY') or self.llm_config.get('api_key')
|
||||
if not api_key:
|
||||
raise ValueError("OpenAI API key not found. Set OPENAI_API_KEY environment variable.")
|
||||
|
||||
base_url = self.llm_config.get('base_url')
|
||||
model_name = self.llm_config.get('model_name')
|
||||
|
||||
if not model_name:
|
||||
raise ValueError("OpenAI model name not specified in config")
|
||||
|
||||
client_kwargs = {'api_key': api_key}
|
||||
if base_url:
|
||||
client_kwargs['base_url'] = base_url
|
||||
|
||||
self.client = OpenAI(**client_kwargs)
|
||||
self.model_name = model_name
|
||||
|
||||
def _initialize_anthropic(self):
|
||||
api_key = os.getenv('ANTHROPIC_API_KEY') or self.llm_config.get('api_key')
|
||||
if not api_key:
|
||||
raise ValueError("Anthropic API key not found. Set ANTHROPIC_API_KEY environment variable.")
|
||||
|
||||
model_name = self.llm_config.get('model_name')
|
||||
if not model_name:
|
||||
raise ValueError("Anthropic model name not specified in config")
|
||||
|
||||
self.client = Anthropic(api_key=api_key)
|
||||
self.model_name = model_name
|
||||
|
||||
def generate(self, prompt, **kwargs):
|
||||
if self.llm_type == 'llama_cpp':
|
||||
llama_kwargs = self._prepare_llama_kwargs(kwargs)
|
||||
response = self.llm(prompt, **llama_kwargs)
|
||||
return response['choices'][0]['text'].strip()
|
||||
elif self.llm_type == 'ollama':
|
||||
return self._ollama_generate(prompt, **kwargs)
|
||||
elif self.llm_type == 'openai':
|
||||
return self._openai_generate(prompt, **kwargs)
|
||||
elif self.llm_type == 'anthropic':
|
||||
return self._anthropic_generate(prompt, **kwargs)
|
||||
else:
|
||||
raise ValueError(f"Unsupported LLM type: {self.llm_type}")
|
||||
|
||||
def _ollama_generate(self, prompt, **kwargs):
|
||||
url = f"{self.base_url}/api/generate"
|
||||
data = {
|
||||
'model': self.model_name,
|
||||
'prompt': prompt,
|
||||
'options': {
|
||||
'temperature': kwargs.get('temperature', self.llm_config.get('temperature', 0.7)),
|
||||
'top_p': kwargs.get('top_p', self.llm_config.get('top_p', 0.9)),
|
||||
'stop': kwargs.get('stop', self.llm_config.get('stop', [])),
|
||||
'num_predict': kwargs.get('max_tokens', self.llm_config.get('max_tokens', 55000)),
|
||||
'num_ctx': self.llm_config.get('n_ctx', 55000)
|
||||
}
|
||||
}
|
||||
response = requests.post(url, json=data, stream=True)
|
||||
if response.status_code != 200:
|
||||
raise Exception(f"Ollama API request failed with status {response.status_code}: {response.text}")
|
||||
text = ''.join(json.loads(line)['response'] for line in response.iter_lines() if line)
|
||||
return text.strip()
|
||||
|
||||
def _openai_generate(self, prompt, **kwargs):
|
||||
try:
|
||||
response = self.client.chat.completions.create(
|
||||
model=self.model_name,
|
||||
messages=[{"role": "user", "content": prompt}],
|
||||
temperature=kwargs.get('temperature', self.llm_config.get('temperature', 0.7)),
|
||||
top_p=kwargs.get('top_p', self.llm_config.get('top_p', 0.9)),
|
||||
max_tokens=kwargs.get('max_tokens', self.llm_config.get('max_tokens', 4096)),
|
||||
stop=kwargs.get('stop', self.llm_config.get('stop', [])),
|
||||
presence_penalty=self.llm_config.get('presence_penalty', 0),
|
||||
frequency_penalty=self.llm_config.get('frequency_penalty', 0)
|
||||
)
|
||||
return response.choices[0].message.content.strip()
|
||||
except Exception as e:
|
||||
raise Exception(f"OpenAI API request failed: {str(e)}")
|
||||
|
||||
def _anthropic_generate(self, prompt, **kwargs):
|
||||
try:
|
||||
response = self.client.messages.create(
|
||||
model=self.model_name,
|
||||
max_tokens=kwargs.get('max_tokens', self.llm_config.get('max_tokens', 4096)),
|
||||
temperature=kwargs.get('temperature', self.llm_config.get('temperature', 0.7)),
|
||||
top_p=kwargs.get('top_p', self.llm_config.get('top_p', 0.9)),
|
||||
messages=[{
|
||||
"role": "user",
|
||||
"content": prompt
|
||||
}]
|
||||
)
|
||||
return response.content[0].text.strip()
|
||||
except Exception as e:
|
||||
raise Exception(f"Anthropic API request failed: {str(e)}")
|
||||
|
||||
def _cleanup(self):
|
||||
"""Force terminate any running LLM processes"""
|
||||
if self.llm_type == 'ollama':
|
||||
try:
|
||||
# Force terminate Ollama process
|
||||
requests.post(f"{self.base_url}/api/terminate")
|
||||
except:
|
||||
pass
|
||||
|
||||
try:
|
||||
# Also try to terminate via subprocess if needed
|
||||
import subprocess
|
||||
subprocess.run(['pkill', '-f', 'ollama'], capture_output=True)
|
||||
except:
|
||||
pass
|
||||
|
||||
def _prepare_llama_kwargs(self, kwargs):
|
||||
llama_kwargs = {
|
||||
'max_tokens': kwargs.get('max_tokens', self.llm_config.get('max_tokens', 55000)),
|
||||
'temperature': kwargs.get('temperature', self.llm_config.get('temperature', 0.7)),
|
||||
'top_p': kwargs.get('top_p', self.llm_config.get('top_p', 0.9)),
|
||||
'stop': kwargs.get('stop', self.llm_config.get('stop', [])),
|
||||
'echo': False,
|
||||
}
|
||||
return llama_kwargs
|
||||
13
requirements.txt
Normal file
13
requirements.txt
Normal file
|
|
@ -0,0 +1,13 @@
|
|||
llama-cpp-python
|
||||
duckduckgo-search
|
||||
colorama
|
||||
requests
|
||||
beautifulsoup4
|
||||
trafilatura
|
||||
readchar
|
||||
keyboard
|
||||
curses-windows; sys_platform == 'win32'
|
||||
tqdm
|
||||
urllib3
|
||||
openai>=1.0.0
|
||||
anthropic>=0.7.0
|
||||
1481
research_manager.py
Normal file
1481
research_manager.py
Normal file
File diff suppressed because it is too large
Load diff
219
strategic_analysis_parser.py
Normal file
219
strategic_analysis_parser.py
Normal file
|
|
@ -0,0 +1,219 @@
|
|||
from typing import List, Dict, Optional, Union
|
||||
import re
|
||||
import logging
|
||||
from dataclasses import dataclass
|
||||
from datetime import datetime
|
||||
|
||||
@dataclass
|
||||
class ResearchFocus:
|
||||
"""Represents a specific area of research focus"""
|
||||
area: str
|
||||
priority: int
|
||||
source_query: str = ""
|
||||
timestamp: str = ""
|
||||
search_queries: List[str] = None
|
||||
|
||||
def __post_init__(self):
|
||||
if not self.timestamp:
|
||||
self.timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
|
||||
if self.search_queries is None:
|
||||
self.search_queries = []
|
||||
|
||||
@dataclass
|
||||
class AnalysisResult:
|
||||
"""Contains the complete analysis result"""
|
||||
original_question: str
|
||||
focus_areas: List[ResearchFocus]
|
||||
raw_response: str
|
||||
timestamp: str = ""
|
||||
confidence_score: float = 0.0
|
||||
|
||||
def __post_init__(self):
|
||||
if not self.timestamp:
|
||||
self.timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
|
||||
|
||||
# Set up logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class StrategicAnalysisParser:
|
||||
"""Enhanced parser with improved pattern matching and validation"""
|
||||
def __init__(self):
|
||||
self.patterns = {
|
||||
'original_question': [
|
||||
r"(?i)original question analysis:\s*(.*?)(?=research gap|$)",
|
||||
r"(?i)original query:\s*(.*?)(?=research gap|$)",
|
||||
r"(?i)research question:\s*(.*?)(?=research gap|$)",
|
||||
r"(?i)topic analysis:\s*(.*?)(?=research gap|$)"
|
||||
],
|
||||
'research_gaps': [
|
||||
r"(?i)research gaps?:\s*",
|
||||
r"(?i)gaps identified:\s*",
|
||||
r"(?i)areas for research:\s*",
|
||||
r"(?i)investigation areas:\s*"
|
||||
],
|
||||
'priority': [
|
||||
r"(?i)priority:\s*(\d+)",
|
||||
r"(?i)priority level:\s*(\d+)",
|
||||
r"(?i)\(priority:\s*(\d+)\)",
|
||||
r"(?i)importance:\s*(\d+)"
|
||||
]
|
||||
}
|
||||
self.logger = logging.getLogger(__name__)
|
||||
|
||||
def parse_analysis(self, llm_response: str) -> Optional[AnalysisResult]:
|
||||
"""Main parsing method with improved validation"""
|
||||
try:
|
||||
# Clean and normalize the response
|
||||
cleaned_response = self._clean_text(llm_response)
|
||||
|
||||
# Extract original question with validation
|
||||
original_question = self._extract_original_question(cleaned_response)
|
||||
if not original_question:
|
||||
self.logger.warning("Failed to extract original question")
|
||||
original_question = "Original question extraction failed"
|
||||
|
||||
# Extract and validate research areas
|
||||
focus_areas = self._extract_research_areas(cleaned_response)
|
||||
focus_areas = self._normalize_focus_areas(focus_areas)
|
||||
|
||||
# Calculate confidence score
|
||||
confidence_score = self._calculate_confidence_score(original_question, focus_areas)
|
||||
|
||||
return AnalysisResult(
|
||||
original_question=original_question,
|
||||
focus_areas=focus_areas,
|
||||
raw_response=llm_response,
|
||||
confidence_score=confidence_score
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
self.logger.error(f"Error in parse_analysis: {str(e)}")
|
||||
return None
|
||||
|
||||
def _clean_text(self, text: str) -> str:
|
||||
"""Clean and normalize text for parsing"""
|
||||
text = re.sub(r'\n{3,}', '\n\n', text)
|
||||
text = re.sub(r'\s{2,}', ' ', text)
|
||||
text = re.sub(r'(\d+\))', r'\1.', text)
|
||||
return text.strip()
|
||||
|
||||
def _extract_original_question(self, text: str) -> str:
|
||||
"""Extract original question with improved matching"""
|
||||
for pattern in self.patterns['original_question']:
|
||||
match = re.search(pattern, text, re.DOTALL)
|
||||
if match:
|
||||
return self._clean_text(match.group(1))
|
||||
return ""
|
||||
|
||||
def _extract_research_areas(self, text: str) -> List[ResearchFocus]:
|
||||
"""Extract research areas with enhanced validation"""
|
||||
areas = []
|
||||
for pattern in self.patterns['research_gaps']:
|
||||
gap_match = re.search(pattern, text)
|
||||
if gap_match:
|
||||
sections = re.split(r'\n\s*\d+[\.)]\s+', text[gap_match.end():])
|
||||
sections = [s for s in sections if s.strip()]
|
||||
|
||||
for section in sections:
|
||||
focus = self._parse_research_focus(section)
|
||||
if focus and self._is_valid_focus(focus):
|
||||
areas.append(focus)
|
||||
break
|
||||
return areas
|
||||
|
||||
def _parse_research_focus(self, text: str) -> Optional[ResearchFocus]:
|
||||
"""Parse research focus with improved validation without reasoning."""
|
||||
try:
|
||||
# Extract area
|
||||
area = text.split('\n')[0].strip()
|
||||
|
||||
# Extract and validate priority
|
||||
priority = self._extract_priority(text)
|
||||
|
||||
# Return ResearchFocus without reasoning
|
||||
return ResearchFocus(
|
||||
area=area,
|
||||
priority=priority
|
||||
)
|
||||
|
||||
except Exception as e:
|
||||
self.logger.error(f"Error parsing research focus: {str(e)}")
|
||||
return None
|
||||
|
||||
def _extract_priority(self, text: str) -> int:
|
||||
"""Extract priority with validation"""
|
||||
for pattern in self.patterns['priority']:
|
||||
priority_match = re.search(pattern, text)
|
||||
if priority_match:
|
||||
try:
|
||||
priority = int(priority_match.group(1))
|
||||
return max(1, min(5, priority))
|
||||
except ValueError:
|
||||
continue
|
||||
return 3 # Default priority
|
||||
|
||||
def _is_valid_focus(self, focus: ResearchFocus) -> bool:
|
||||
"""Validate research focus completeness and quality"""
|
||||
if not focus.area: # Only check if area exists and isn't empty
|
||||
return False
|
||||
if focus.priority < 1 or focus.priority > 5:
|
||||
return False
|
||||
return True
|
||||
|
||||
def _normalize_focus_areas(self, areas: List[ResearchFocus]) -> List[ResearchFocus]:
|
||||
"""Normalize and validate focus areas"""
|
||||
normalized = []
|
||||
for area in areas:
|
||||
if not area.area.strip():
|
||||
continue
|
||||
|
||||
area.priority = max(1, min(5, area.priority))
|
||||
|
||||
if self._is_valid_focus(area):
|
||||
normalized.append(area)
|
||||
|
||||
# Sort by priority (highest first) but don't add any filler areas
|
||||
normalized.sort(key=lambda x: x.priority, reverse=True)
|
||||
|
||||
return normalized
|
||||
|
||||
def _calculate_confidence_score(self, question: str, areas: List[ResearchFocus]) -> float:
|
||||
"""Calculate confidence score for analysis quality"""
|
||||
score = 0.0
|
||||
|
||||
# Question quality (0.3)
|
||||
if question and len(question.split()) >= 3:
|
||||
score += 0.3
|
||||
|
||||
# Areas quality (0.7)
|
||||
if areas:
|
||||
# Valid areas ratio (0.35) - now based on proportion that are valid vs total
|
||||
num_areas = len(areas)
|
||||
if num_areas > 0: # Avoid division by zero
|
||||
valid_areas = sum(1 for a in areas if self._is_valid_focus(a))
|
||||
score += 0.35 * (valid_areas / num_areas)
|
||||
|
||||
# Priority distribution (0.35) - now based on having different priorities
|
||||
if num_areas > 0: # Avoid division by zero
|
||||
unique_priorities = len(set(a.priority for a in areas))
|
||||
score += 0.35 * (unique_priorities / num_areas)
|
||||
|
||||
return round(score, 2)
|
||||
|
||||
def format_analysis_result(self, result: AnalysisResult) -> str:
|
||||
"""Format analysis result for display without reasoning."""
|
||||
formatted = [
|
||||
"Strategic Analysis Result",
|
||||
"=" * 80,
|
||||
f"\nOriginal Question Analysis:\n{result.original_question}\n",
|
||||
f"Analysis Confidence Score: {result.confidence_score}",
|
||||
"\nResearch Focus Areas:"
|
||||
]
|
||||
|
||||
for i, focus in enumerate(result.focus_areas, 1):
|
||||
formatted.extend([
|
||||
f"\n{i}. {focus.area}",
|
||||
f" Priority: {focus.priority}"
|
||||
])
|
||||
|
||||
return "\n".join(formatted)
|
||||
149
web_scraper.py
Normal file
149
web_scraper.py
Normal file
|
|
@ -0,0 +1,149 @@
|
|||
import requests
|
||||
from bs4 import BeautifulSoup
|
||||
from urllib.robotparser import RobotFileParser
|
||||
from urllib.parse import urlparse, urljoin
|
||||
import time
|
||||
import logging
|
||||
from concurrent.futures import ThreadPoolExecutor, as_completed
|
||||
import re
|
||||
|
||||
# Set up logging
|
||||
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class WebScraper:
|
||||
def __init__(self, user_agent="WebLLMAssistant/1.0 (+https://github.com/YourUsername/Web-LLM-Assistant-Llama-cpp)",
|
||||
rate_limit=1, timeout=10, max_retries=3):
|
||||
self.session = requests.Session()
|
||||
self.session.headers.update({"User-Agent": user_agent})
|
||||
self.robot_parser = RobotFileParser()
|
||||
self.rate_limit = rate_limit
|
||||
self.timeout = timeout
|
||||
self.max_retries = max_retries
|
||||
self.last_request_time = {}
|
||||
|
||||
def can_fetch(self, url):
|
||||
# parsed_url = urlparse(url)
|
||||
# robots_url = f"{parsed_url.scheme}://{parsed_url.netloc}/robots.txt"
|
||||
# self.robot_parser.set_url(robots_url)
|
||||
# try:
|
||||
# self.robot_parser.read()
|
||||
# return self.robot_parser.can_fetch(self.session.headers["User-Agent"], url)
|
||||
# except Exception as e:
|
||||
# logger.warning(f"Error reading robots.txt for {url}: {e}")
|
||||
return True # ignore robots.txt
|
||||
|
||||
def respect_rate_limit(self, url):
|
||||
domain = urlparse(url).netloc
|
||||
current_time = time.time()
|
||||
if domain in self.last_request_time:
|
||||
time_since_last_request = current_time - self.last_request_time[domain]
|
||||
if time_since_last_request < self.rate_limit:
|
||||
time.sleep(self.rate_limit - time_since_last_request)
|
||||
self.last_request_time[domain] = time.time()
|
||||
|
||||
def scrape_page(self, url):
|
||||
if not self.can_fetch(url):
|
||||
logger.info(f"Robots.txt disallows scraping: {url}")
|
||||
return None
|
||||
|
||||
for attempt in range(self.max_retries):
|
||||
try:
|
||||
self.respect_rate_limit(url)
|
||||
response = self.session.get(url, timeout=self.timeout)
|
||||
response.raise_for_status()
|
||||
return self.extract_content(response.text, url)
|
||||
except requests.RequestException as e:
|
||||
logger.warning(f"Error scraping {url} (attempt {attempt + 1}/{self.max_retries}): {e}")
|
||||
if attempt == self.max_retries - 1:
|
||||
logger.error(f"Failed to scrape {url} after {self.max_retries} attempts")
|
||||
return None
|
||||
time.sleep(2 ** attempt) # Exponential backoff
|
||||
|
||||
def extract_content(self, html, url):
|
||||
soup = BeautifulSoup(html, 'html.parser')
|
||||
|
||||
# Remove unwanted elements
|
||||
for element in soup(["script", "style", "nav", "footer", "header"]):
|
||||
element.decompose()
|
||||
|
||||
# Extract title
|
||||
title = soup.title.string if soup.title else ""
|
||||
|
||||
# Try to find main content
|
||||
main_content = soup.find('main') or soup.find('article') or soup.find('div', class_='content')
|
||||
|
||||
if main_content:
|
||||
paragraphs = main_content.find_all('p')
|
||||
else:
|
||||
paragraphs = soup.find_all('p')
|
||||
|
||||
# Extract text from paragraphs
|
||||
text = ' '.join([p.get_text().strip() for p in paragraphs])
|
||||
|
||||
# If no paragraphs found, get all text
|
||||
if not text:
|
||||
text = soup.get_text()
|
||||
|
||||
# Clean up whitespace
|
||||
text = re.sub(r'\s+', ' ', text).strip()
|
||||
|
||||
# Extract and resolve links
|
||||
links = [urljoin(url, a['href']) for a in soup.find_all('a', href=True)]
|
||||
|
||||
return {
|
||||
"url": url,
|
||||
"title": title,
|
||||
"content": text[:2400], # Limit to first 2400 characters
|
||||
"links": links[:10] # Limit to first 10 links
|
||||
}
|
||||
|
||||
def scrape_multiple_pages(urls, max_workers=5):
|
||||
scraper = WebScraper()
|
||||
results = {}
|
||||
|
||||
with ThreadPoolExecutor(max_workers=max_workers) as executor:
|
||||
future_to_url = {executor.submit(scraper.scrape_page, url): url for url in urls}
|
||||
for future in as_completed(future_to_url):
|
||||
url = future_to_url[future]
|
||||
try:
|
||||
data = future.result()
|
||||
if data:
|
||||
results[url] = data
|
||||
logger.info(f"Successfully scraped: {url}")
|
||||
else:
|
||||
logger.warning(f"Failed to scrape: {url}")
|
||||
except Exception as exc:
|
||||
logger.error(f"{url} generated an exception: {exc}")
|
||||
|
||||
return results
|
||||
|
||||
# Function to integrate with your main system
|
||||
def get_web_content(urls):
|
||||
scraped_data = scrape_multiple_pages(urls)
|
||||
return {url: data['content'] for url, data in scraped_data.items() if data}
|
||||
|
||||
# Standalone can_fetch function
|
||||
def can_fetch(url):
|
||||
# parsed_url = urlparse(url)
|
||||
# robots_url = f"{parsed_url.scheme}://{parsed_url.netloc}/robots.txt"
|
||||
# rp = RobotFileParser()
|
||||
# rp.set_url(robots_url)
|
||||
# try:
|
||||
# rp.read()
|
||||
# return rp.can_fetch("*", url)
|
||||
# except Exception as e:
|
||||
# logger.warning(f"Error reading robots.txt for {url}: {e}")
|
||||
return True # ignore robots.xt
|
||||
|
||||
if __name__ == "__main__":
|
||||
test_urls = [
|
||||
"https://en.wikipedia.org/wiki/Web_scraping",
|
||||
"https://example.com",
|
||||
"https://www.python.org"
|
||||
]
|
||||
scraped_content = get_web_content(test_urls)
|
||||
for url, content in scraped_content.items():
|
||||
print(f"Content from {url}:")
|
||||
print(content[:500]) # Print first 500 characters
|
||||
print("\n---\n")
|
||||
Loading…
Add table
Reference in a new issue